
打脸!GPT-4o输出长度8k齐拼凑,陈丹琦团队最新LLM基准测试

许多大模子的官方参数齐宣称我方可以输出长达32K tokens的内容,但这数字施行上是存在水分的??
最近,陈丹琦团队提议了一个全新的基准测试器具LONGPROC,专门用于检测长高下文模子处理复杂信息并生成回答的手艺。

实验遵守有点令东说念主只怕,团队发现,包括GPT-4o等起初进的模子在内,尽管模子在常用长高下文回忆基准上弘扬出色,但在处理复杂的长文生成任务时仍有很大的考订空间。
具体来说,测试的通盘模子齐宣称我方高下文窗口大小朝上32K tokens,但开源模子一般在2K tokens任务中就弘扬欠安,而GPT-4o等闭源模子在8K tokens任务中性能也较着着落。
例如来说,让GPT-4o模子生成一个详备的旅行筹算时,即使提供了干系的时期节点和直飞航班清醒,在模子的生顺利率中仍然出现了不存在的航班信息,也便是出现了幻觉。

这到底是若何回事呢?
全新LONGPROC基准当今现存的长高下文讲话模子(long-context language models)的评估基准主要聚拢在长高下文回忆任务上,这些任务要求模子在处理渊博无关信息的同期生成浅显的响应,莫得充分评估模子在整合分布信息和生成长输出方面的手艺。
为了进一步精准检测模子处理长高下文并生成回答的手艺,陈丹琦团队提议了全新的LONGPROC基准测试。
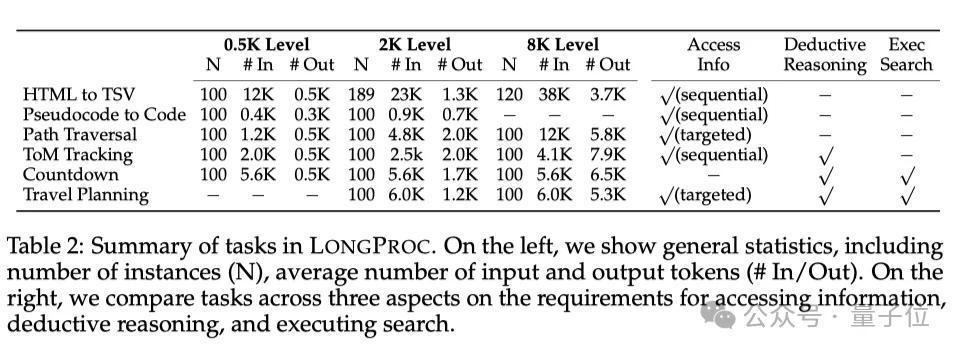
从表1中各测试基准的对比可以看出,唯有LONGPROC基准同期答允6个要求,包括复杂的经过、要求模子输出大于1K tokens、且提供细则性的处置决策等。

新基准包含的任务
具体来说,LONGPROC包含6个不同的生成任务:
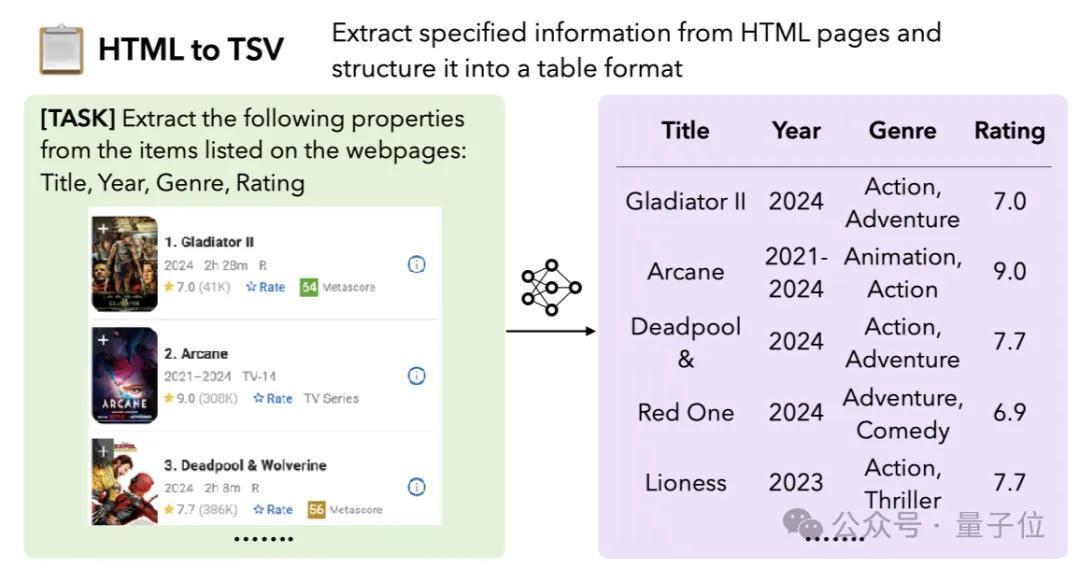
1.HTML到TSV:要求模子从HTML页面中提真金不怕火指定信息并花样化为表格。需要从复杂的HTML结构中稳固地提真金不怕火通盘干系信息,并将其正确花样化。
比如从底下的网页中提真金不怕火出通盘影片的信息:
2.伪代码生成代码:要求模子将伪代码翻译成C++代码。需要保捏源代码和目的代码之间的逐一双应关系,并确保翻译的正确性。
3.旅途遍历:要求模子在假定的环球交通网罗中找到从一个城市到另一个城市的旅途。需要确保旅途的独一性和正确性。
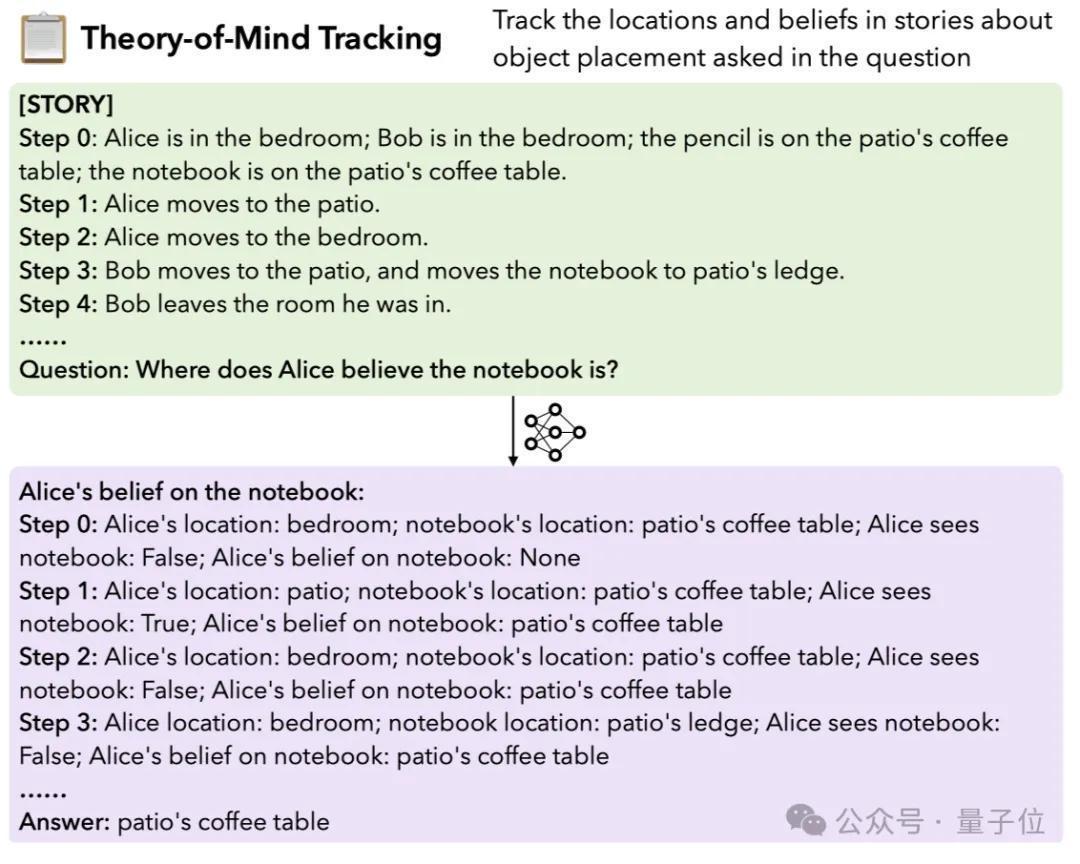
4.Theory-of-Mind追踪:要求模子追踪故事中对象位置的念念想变化。需要进行长距离的推理,以准确反馈对象在不同时期点的位置和情状。
比如把柄底下的翰墨敷陈估量出“Alice以为条记本在那处”:
5.Countdown游戏:要求模子使用四个数字和基本算术操作找到达到目的数字的设施。需要进行深度优先搜索,并确保搜索过程的完好性和正确性。
比如鄙人面的示例中,要求模子用四则运算操作输入的数字,最终得出29的遵守:

6.旅行筹算:要求模子生成答允多种敛迹的多城市旅行经营。需要探索多种可能的行程安排,并确保通盘敛迹条目得到答允。
如下图所示,图中要求模子把柄任务提供的欧洲行程经营和直飞航班筹算最好的旅行时期安排:

在输出遵守的同期,LONGPROC还会要求模子在履行详备设施提醒的同期生成结构化的长神气输出 。
从表2中可以看出,除了对比左边的实例数目(N)、输入和输出tokens的平均数目(#In/#Out),团队还会从表格最右3列的获取信息的方式、是否存在演绎推理和履行搜索这三个方濒临任务进行比较。
实验任务竖立
实验中,上头的6个任务齐有不同的数据集。例如,HTML到TSV任务使用了Arborist数据聚拢的56个网站;伪代码生成代码任务使用了SPOC数据集;旅途遍历任务构建了一个假定的环球交通网罗等等。
实验齐会要求模子履行一个详备的设施来生成输出。
此外,把柄任务的输出长度,数据集中被分为500 tokens、2K tokens和8K tokens三个难度级别。比如关于HTML到TSV任务来说,每个网站齐会被分割成非重迭子样本,这么就可以得到更多数据点。
参与实验的模子包括17个模子,包括流行的闭源模子(如GPT-4o、Claude 3.5、Gemini 1.5)和开源模子(如ProLong、Llama-3、Mistral-v0.3、Phi-3、Qwen-2.5、Jamba)。
实验遵守及分析领先来望望实验中模子的全体弘扬。
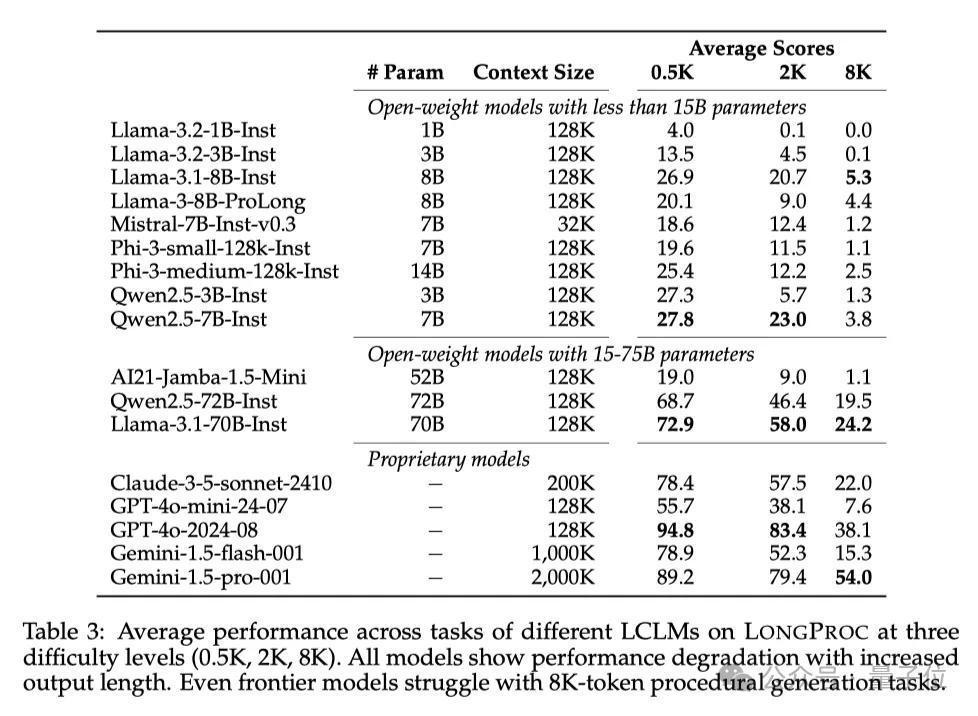
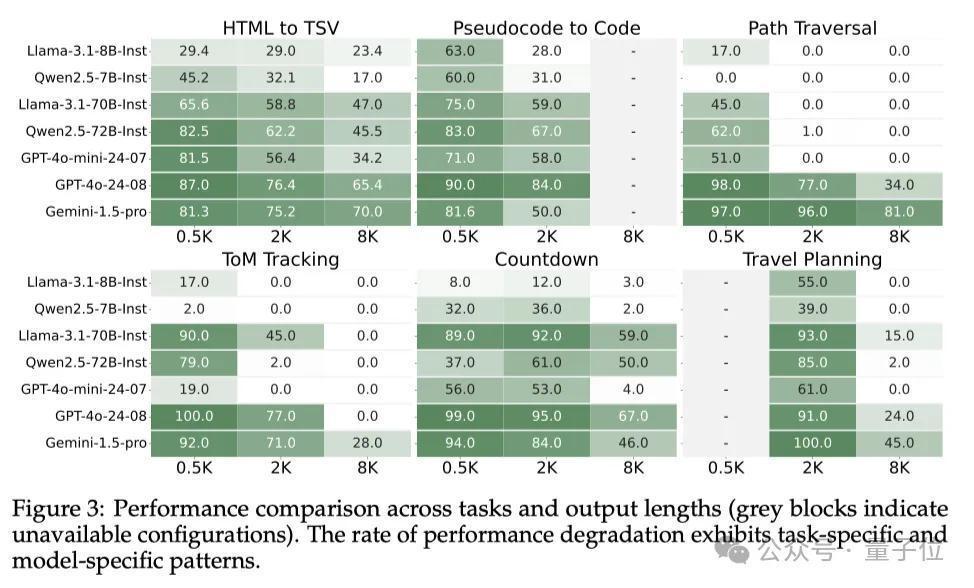
遵守有点令东说念主只怕,通盘模子在长设施生成任务中齐弘扬出权贵的性能着落!具体的数值可以稽查底下的表3。
即使是GPT-4o这种前沿模子,在8K tokens的输出任务上也难以保捏稳固的弘扬。
咱们再来详备分析一下不同模子之间的相反。
把柄底下的图3可以看出,像GPT-4o这么的顶尖闭源模子在0.5K任务上弘扬最好,但在8K任务上性能权贵着落。
小限度的开源模子基本齐弘扬欠安,而中等限度的开源模子(Llama-3.1-70B-Instruct)在低难度任务上弘扬与GPT-4o进出不大。
不外,在某些8K任务上,中等限度的模子弘扬很可以,比如Gemini-1.5-pro在HTML to TSV任务中就朝上了GPT-4o,Llama-3.1-70B-Instruct、Qwen2.5-72B-Instruct在8K的Countdown游戏中也与GPT-4o进出不大。
但全体来看,开源模子的性能还是不足闭源模子。
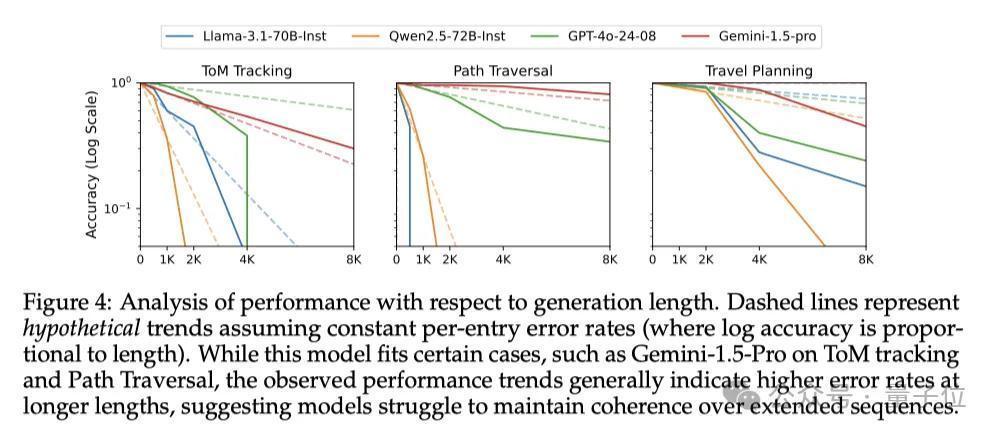
此外,模子弘扬跟任务类型也关筹议。在需要更长推理的任务中,模子的性能渊博出现了更权贵的着落。
如图4所示,在Theory-of-Mind追踪、Countdown游戏和旅行筹算任务这些需要处理更复杂的信息、进行更长链的推理的任务中,模子性能的着落幅度齐更大,GPT-4o、Qwen等模子的精准度致使直线着落。
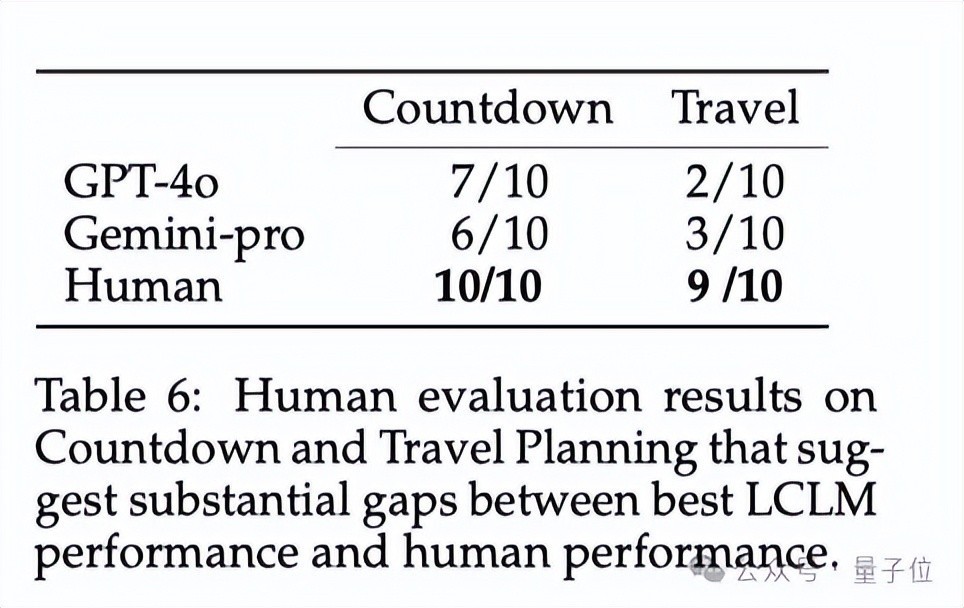
除了对比17个模子之间的手艺,团队成员还将弘扬较好的模子输出内容与东说念主类输出进行了对比。
从表6的遵守中可以看出,与东说念主类手艺比较,现时模子还存在权贵差距。
东说念主类在Countdown游戏和旅行筹算任务均分歧处置了10个和9个问题,而最好的模子GPT-4o分歧只处置了7个和3个问题。
总体来说,本论文提议的LONGPROC测试基准灵验地评估了模子在长设施生成任务方面的弘扬,是对现存基准的一个补充。
实验发现,即使是起初进的模子,在生成连贯的长段内容方面仍然有很大的考订空间。
尤其是在要求输出8k tokens的任务中,参数较大的先进模子也弘扬欠安,这可能是曩昔LLM筹议的一个非常特兴味兴味的观点。
一作是清华学友这篇论文的一作是本科毕业于清华软件学院的Xi Ye(叶曦),之后从UT Austin计较机科学系得到了博士学位。
清华特奖得主Tianyu Gao(高天宇)也有参与这篇论文:

据一作Xi Ye的个东说念主主页显现,他的筹议主要聚拢在当然讲话处理鸿沟,重心是提升LLM的可发挥注解性并增强其推理手艺,此外他还从事语义贯通和设施轮廓的干系责任。

当今他是普林斯顿大学讲话与智能实验室(PLI)的博士后筹议员,还将从 2025 年 7 月初始加入阿尔伯塔大学(University of Alberta)担任助理栽培。
PS:他的主页也正在招收25届秋季全奖博/硕士生哦
参考麇集:
[1]https://arxiv.org/pdf/2501.05414[2]https://xiye17.github.io/— 完 —
量子位 QbitAI · 头条号签约
热心咱们,第一时期获知前沿科技动态