
若何高效的将智驾AI大模子软件模块部署到SOC芯片上?

在自动驾驶行业发展的烈烈轰轰地今天,开发大模子关于其在多样通用场景和要道场景的应用齐显得相配的必要了。大模子的开发不仅不错很好的助力以数据驱动为中枢的端到端的应用,也不错在后续芯片算力大幅度擢升后终了更好的识别成果。可是,议论到面前应用于车端的智驾域控芯片仍然普及于中低算力芯片,因此,议论若何选用一定的步调战略将一样transformer这么的AI大模子要素高效的部署到SoC芯片上,这不仅不错权臣擢升系统的反映速率、功耗效率和安全性,同期也不错很好的称心实时性强、资源受限环境下的应用需求。
在自动驾驶软件缱绻中,将Transformer模子部署到蚁合式SoC芯片上触及到多个要道要领。以下是具体的示例和讲明:
1ONE模子优化+剪枝1、量化(Quantization)
例如,将用于感知系统的Transformer模子从32位浮点数目化到8位整数,以减少计较资源占用和内存需求。这不错在不权臣驳斥精度的情况下,加速自动驾驶中物体检测和识别的速率。
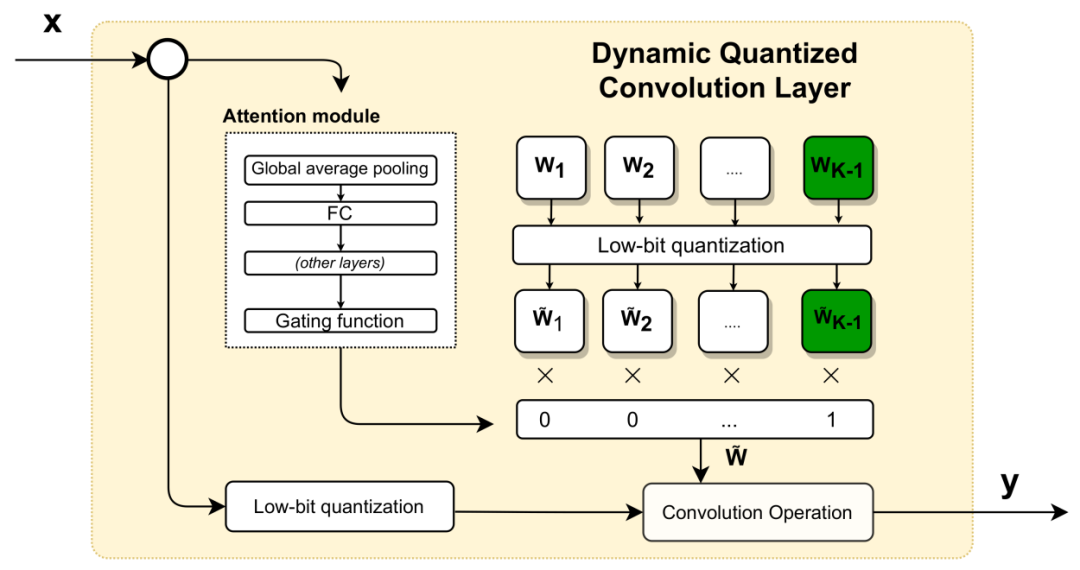
率先在模子准备阶段,确保Transformer模子已经经过充分的预教师,在32位浮点数精度下大致达到预期的精度和性能,该模子将看成量化的基础模子。而在数据采集阶段,采集迷漫的感知数据,如自动驾驶中的图像、点云数据,用于量化经由中模子的校准和微调。在后续的量化感知系统的Transformer模子阶段,分为静态量化(Post-Training Quantization)和动态量化(Dynamic Quantization)。确保在量化经由中,模子输入的动态鸿沟被充分议论,高出是在感知系统中,输入数据(如图像)平方具有较大的动态鸿沟。在梯度褪色问题上,在模子量化后,就怕会遭受梯度褪色的问题,高出是在深度Transformer模子中。不错通过微妥协量化感知(Quantization-Aware Training)本事来减轻这一问题。
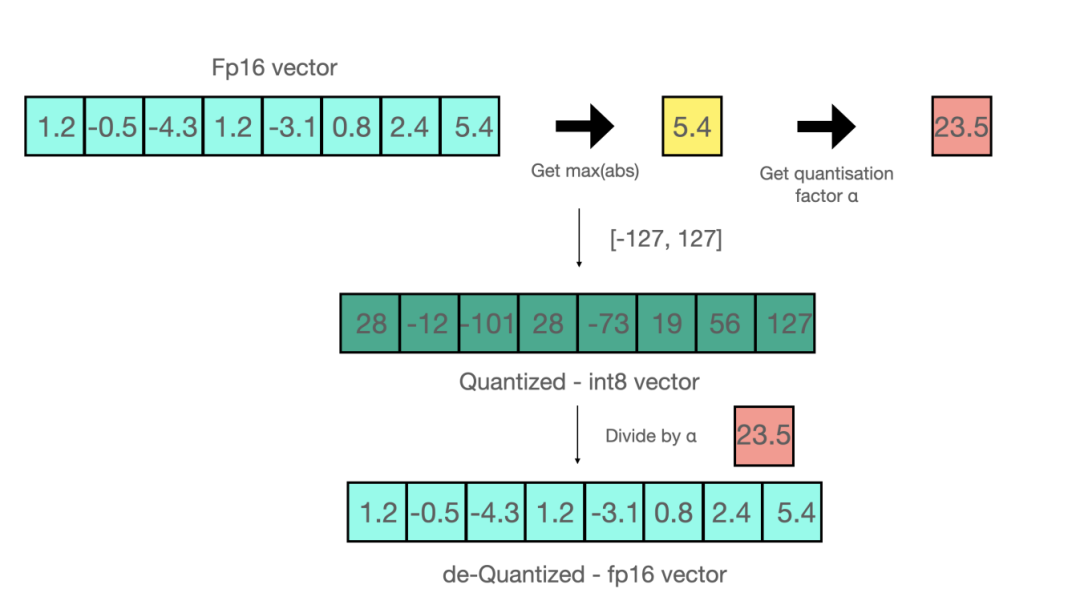
在量化感知教师(Quantization-Aware Training, QAT)阶段中,模子在教师时模拟8位整数的计较经由。通过在教师中引入量化噪声,模子渐渐适合量化后的精度变化。具体操作是在教师经由中,将32位浮点数革新为8位整数进行前向传播,而反向传播仍在32位浮点数下进行。这种作念法的上风是量化感知教师时不错权臣提高量化后的模子精度,高出是在自动驾驶感知任务中,需要缜密检测和分类的情况下。
虽然,在量化后模子考据阶段,通过精度评估,使用感知数据集评算计化前后的模子精度各异,确保量化后的模子大致在实质场景中保握迷漫的检测和识别精度。在性能评估阶段, 在车载SoC上部署量化后的Transformer模子,测试其推理速率和计较资源耗尽,以考据量化的成果。
2、剪枝(Pruning)
对自动驾驶中的Transformer模子进行剪枝(Pruning)是一种减少模子鸿沟和计较复杂度的灵验步调。尤其在资源受限的环境中,如车载SoC芯片上使用感知算法进行车说念线检测时,对自动驾驶中的Transformer模子进行剪枝,去除对车说念线检测影响较小的权重。这么不错减少模子大小,使其更容易部署在SoC上。
假定在自动驾驶系统中,使用了一个Transformer模子来进行车说念线检测和阻碍物识别。模子中包含8个细心力头。经过分析发现,某些细心力头对特定场景的孝敬较小(例如,一些头对远距离的车说念线怜惜较少,而此时车速较低)。不错采用将这些细心力头进行剪枝,从而减少计较复杂度,同期通过微调保握合座模子的检测才气。剪枝后重新教师模子,以确保在万般驾驶场景中的准确性。这种步调有助于在保管高性能的前提下,驳斥模子在自动驾驶场景中的计较支出,适合车载SoC的限制。
1)剪枝旨趣分析
率先,是基于自动驾驶场景笃定剪枝指标。这一指标包括剪枝率(Pruning Rate)和剪枝战略。剪枝率决定模子中要移除的参数比例,关于自动驾驶场景,平方需要在精度和效率之间取得均衡,因此剪枝率需要左证具体应用场景进行挽救。而在剪枝战略方面,采用剪枝的对象,如剪掉部分心经元、细心力头、层或特定权重连结,不错去除对最终推理终结影响较小的部分。
在剪枝对象采用上,主要领受层级剪枝(Layer-wise Pruning)。针对Transformer模子的不同档次进行剪枝。例如,移除在特定自动驾驶场景(如简便的车说念保握任务)中不常用的细心力头(Attention Head)或过剩的全连结层(Feedforward Network)。左证权重进行剪枝(Weight Pruning),移除权重值接近于零的连结。通过分析Transformer模子的权重漫衍,采用那些对输出影响较小的权重进行剪枝。比如基于细心力头剪枝(Head Pruning)经由中,需要充分议论Transformer中的多头细心力机制允许模子怜惜不同的特征。通过评估每个头的孝敬,不错移除那些在自动驾驶场景中作用较小的头。
2)剪枝战略
基于以上剪枝步调论,剪枝步调不错分为全局剪枝(Global Pruning)、层级剪枝(Layer-wise Pruning)和结构化剪枝(Structured Pruning)。
全局剪枝在总共这个词模子鸿沟内左证权重的齐全值大小进行剪枝。比如,移除总共低于某一阈值的权重,无论其场地的层或模块。层级剪枝是针对特定层或模块进行剪枝。这种步调不错更好地限度每一层的剪枝率,确保不会过度减弱某些要道层的才气。通过移除总共这个词神经元或通说念,而不是单个权重,这种步调更安妥硬件加速器。比如,在自动驾驶的Transformer模子中,移除对交通璀璨检测孝敬较小的某一层的整组神经元(如动态车辆检测,因为其与交通璀璨的检测存在彰着的判袂区别)。
3)剪枝后微调(Fine-Tuning)
剪枝后,模子可能会出现性能着落。通过重新教师,模子不错重新学习并适合被剪枝后的结构,这个经由有助于规复剪枝前的精度水平。这仍是由不错领受缓缓剪枝和微调相勾通的战略,每次剪去一小部均权重后立即进行微调,而不是一次性剪去渊博权重。
在典型的自动驾驶任务中(如阻碍物检测、车说念线识别)评估剪枝后模子的性能。确保剪枝后的模子在要道任务中的精度和反映时辰称心要求。在资源评估经由中,比较剪枝前后模子的计较资源占用,包括推理时辰、内存占用和功耗,以笃定剪枝的灵验性。
4)部署与监控
将剪枝后的Transformer模子部署到车载SoC上,再在实质驾驶场景中进行部署测试,不错确保模子的实时性和踏实性。实时监控剪枝后模子的开动知道,左证实质需求动态挽救模子结构或进一步进行剪枝和优化。在自动驾驶中,不错使用一个教师好的大鸿沟Transformer模子(如BERT)来教师一个更小的模子(如TinyBERT),用于车内低功耗的SoC芯片上,以终了车内实时场景意会,该经由一般称之为常识蒸馏(Knowledge Distillation)。
3ONE硬件加速与内存管制1、硬件加速
使用专用加速器(Accelerators),在自动驾驶的蚁合式SoC上,平方会有NPU(神经集聚处理单位)来加速Transformer模子的推理。例如,在处理前列车辆的动态分析时,使用NPU不错大幅擢升Transformer模子的处理速率。
针对神经集聚优化的架构,由于领受了特别的硬件缱绻,比如NPU专为深度学习模子缱绻,包含渊博并行处理单位,大致高效处理神经集聚中的矩阵乘法、卷积等运算。Transformer模子中,渊博的矩阵运算(如多头细心力机制中的点积操作)是计较的主要瓶颈。NPU大致通过并行处理这些操作,大幅加速计较速率。同期,NPU平方集成有高带宽的片上存储器,用于快速存取模子参数和中间终结,产生低蔓延和高带宽存储的效力。比拟于传统的CPU或GPU,NPU的存储器蔓延更低,大致减少数据传输瓶颈,提高Transformer模子的处理效率。
在并行计较才气方面,基于Transformer的AI大模子中的多头细心力机制需要并行计较多个细心力头的权重和输出。Transformer模子不错在SoC上的多核架构中并行开动,如将多头细心力机制中的各个头分派到不同的核上,以加速处理车说念检测和阻碍物识别的速率。在NPU上,将这些计较任务分派到多个处理单位并行推行,不错权臣加速合座计较速率。由于NPU不错同期处理Transformer模子的不同层级,通过活水线或分层处理的形势不错灵验的减少推理蔓延。在处理前列车辆的动态分析时,NPU不错在同期处理多个输入帧的情况下保握高蒙眬量。
在加速矩阵运算方面,Transformer模子中,要道的计较如细心力机制和前馈神经集聚(Feedforward Neural Network)齐依赖于大鸿沟的矩阵乘法运算。NPU在矩阵运算上具有极高的效率,大致大幅度裁减这些计较的推行时辰。好多NPUs配备了专用的深度学习辅导集,这些辅导集不错在硬件层面优化矩阵运算,使得计较资源得以最大化期骗。
在减少数据移动的支出上,Transformer模子在计较经由中需要通常地进行内存拜谒。如果在传统的计较架构中,数据的通常移动会激发较大的蔓延,而NPU通过在片上存储器中存储更多的数据并优化拜谒形式,不错减少内存带宽的瓶颈,从而提高处理速率。同期,NPU不错将计较和存储进行灵验勾通。通过将计较单位和存储单位紧密集成的形势,减少数据在计较单位和存储单位之间传输的蔓延。这关于处理前列车辆的实时动态分析至关弥留,因为系统不错在短时辰内完成渊博数据的处理和决议。
临了,NPU不错终了芯片异构计较和任务分离,将复杂运算卸载给NPU。在自动驾驶系统中,NPU不错特别用于处理复杂的深度学习任务,如Transformer模子的推理,而将其他任务(如系统限度、传感器数据预处理)分派给CPU或DSP。同期,动态分析前列车辆需要系统在极短的时辰内作念出决议,高效处理实时性要求高的任务。据统计,NPU不错在毫秒级别完成对多帧图像或点云数据的推理,确保系统大致实时反映外部环境的变化。这种任务分离和异构计较大致更好地期骗系统资源,提高合座性能。
2、内存中Transformer架构优化
自动驾驶中,Transformer模子处理的图像数据量大,需要优化内存管制。例如,使用内存池本事复用内存空间,从而减少因屡次加载数据导致的带宽占用。
如下图清晰内存中的Transformer 集聚架构,iMTransformer (In-Memory Transformer)以 Bank、Tile 和 Mat 的分层形式进行组织。这种分层形式顺从现存的内存分层结构和 Transformer 集聚的分层形式。iMTransformer (A) 由编码器 (B) 妥协码器 (C) 组构成。编码器组由编码器 MHA 瓦片 (D) 和 FF 瓦片以及归一化单位构成。解码器组由两个解码器 MHA 瓦片 (E)、一个 FF 瓦片和一个归一化单位构成。编码器 (D) 妥协码器 (E) MHA 瓦片由 AH Mats (F) 和团员器单位构成。
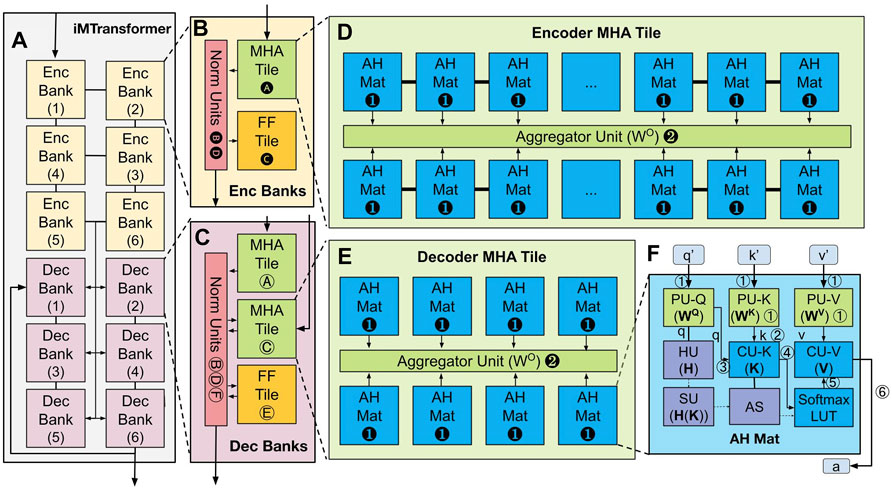
iMTransformer 顺从分层内存结构
这里例如讲明一下要若何期骗内存池本事进行优化缱绻。在自动驾驶SoC中,将常用的神经集聚参数缓存在片上内存中,加速模子推理经由,假定在自动驾驶系统中,使用Transformer模子对前列车辆进步履态分析。每次处理一帧图像或点云数据时,模子需要加载新的数据,并存储计较经由中的中间终结。每帧数据处理完成后,这些存储空间不错立即被开释和复用。
总共这个词操作经由中,需要在模子的每个处理要领中,率先尝试从内存池均分派内存。如果内存池中有合适的闲隙块,则径直使用,不然苦求新的内存块。当这一步计较完成而况中间终结不再需要时,将内存块复返到内存池中,以供下一步使用。通过使用内存池本事,不错权臣减少因通常的数据加载和内存分派导致的内存带宽占用。在实质系统中,不错通过监控内存使用情况和带宽期骗率,评估内存池本事的成果。由于减少了内存分派和开释的支出,系统合座的反映速率将得到提高,高出是在处理一语气数据流时(如视频帧或点云序列),内存池的上风愈加彰着。
4ONE软件框架/库援助与能耗优化基于transformer这类并走运算的大模子深度学习框架中,不错使用如TensorFlow Lite的镶嵌式版蓝本加载和开动Transformer模子,特别针对自动驾驶SoC的优化,减少蔓延和功耗。例如,使用TensorFlow Lite来开动一个针对交通璀璨识别的Transformer模子。在图编译器(Graph Compiler)时,使用TVM等用具将模子编译成优化的二进制代码,以便在SoC上高效推行。比如,将Transformer模子用于实时行东说念主检测的推理。
假定你正在自动驾驶感知系统中使用 Transformer 模子进行车辆识别和动态分析。率先需要将已经教师好的 Transformer 模子(用于识别前列车辆)革新为 TensorFlow Lite 阵势,并进行量化,将模子权重从 32 位浮点数目化为 8 位整数。如下图清晰全整数目化(Full Integer Quantization)的代码默示图。
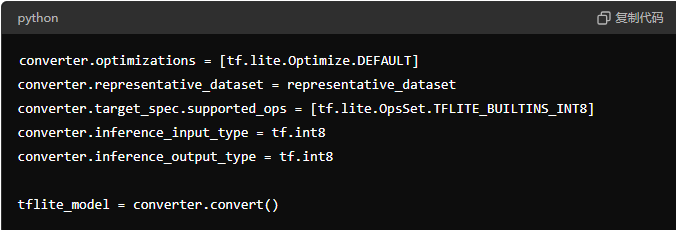
将模子部署到自动驾驶 SoC 上时,不错使用 SoC 的 NPU 或 DSP 进行硬件加速,确保模子推理时在毫秒级别内完成。通过剪枝和批处理优化,进一步减少模子在推理经由中所需的内存和计较资源,从而驳斥 SoC 的功耗。
在能耗优化方面,动态革新电压和频率(DVFS)。左证自动驾驶场景的复杂性挽救SoC的电压和频率。例如,在高速公路上进行自动驾驶时,由于环境较简便,不错驳斥SoC开动处理频率来松懈能耗。而在复杂城市路况时,提高频率不错保证模子的实时性。在低功耗缱绻中,在缱绻自动驾驶Transformer模子时,领受更少的计较资源和高效的算法,如使用轻量级Transformer结构进行车辆追踪。
5ONE测锻真金不怕火证与部署热爱临了,使用自动驾驶仿真平台(如CARLA)来模拟Transformer模子在多样驾驶场景中的知道,考据其在SoC上的性能是否适当实时要求。左证仿真终结,挽救Transformer模子的结构,优化SoC的开动参数,如在检测夜间行东说念主时,擢升模子的细心力机制,以提高识别精度。在车辆的OTA更新中,推送新的优化后的Transformer模子,使其在SoC上开动时能更好地搪塞最新的路况和场景。
在辛苦监控与调优经由中,通过车载系统实时监控部署在SoC上的Transformer模子的性能,如检测模子在不同天气要求下的知道,并左证需要辛苦进行调优或更新。
6ONE以实例莳植若何作念好临了化软件部署以下将以实例完满的讲明若何将Transformer模子革新、优化并部署到自动驾驶SoC上,从而在资源受限的环境中终了高效、实时的感知和决议。
要领一:准备和教师原始Transformer模子
采用合适的模子架构,笃定自动驾驶中要惩处的具体任务。例如物体检测是识别和定位说念路上的车辆、行东说念主、交通璀璨等。车说念检测是识别说念路车说念线。场景意会是分析合座驾驶环境。左证任务采用安妥的Transformer模子架构,例如Vision Transformer(ViT) 适用于图像分类和物体检测。DETR(Detection Transformer)专为物体检测缱绻。Swin Transformer适用于高效图像识别。
在数据集准备和模子教师阶段,采集渊博高质地的自动驾驶议论数据,并进行准确的标注。在模子教师阶段,使用TensorFlow框架在高性能计较环境中教师模子,确保模子达到预期的准确度和性能。
要领二:将模子革新为TensorFlow Lite阵势
通过装配必要的用具和库,便不错编写革新剧本进行基本模子革新,应用模子进行必要的量化(比如动态鸿沟量化、整数目化、全整数目化),并在教师经由中应用剪枝终了疏淡化。
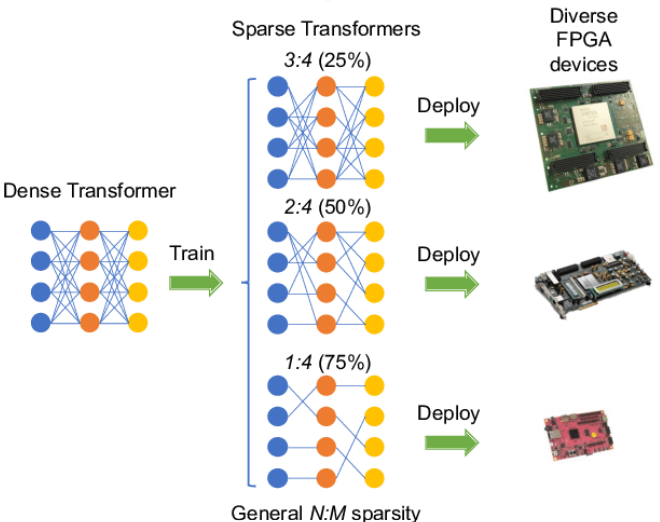
如下图清晰了一种使用当代 Ampere GPU 和不同的 FPGA 来加速基于 N:M 疏淡 Transformer 的模子。通过生成一系列 N:M 疏淡 Transformer 以及专用加速器,不错终了高效的模子部署。
要领三:针对自动驾驶SoC进行特定优化
经由中需要笃定SoC的硬件特点和援助的量化阵势,主如若通过了解SoC援助的辅导集和加速器。证明SoC是否援助INT8运算,以及是否有特别的硬件援助。
DSP(数字信号处理器):安妥处理信号和图像数据。
NPU(神经集聚处理单位):专为深度学习推理加速缱绻。
GPU(图形处理单位):安妥并行处理渊博数据。
TensorFlow Lite提供了多种Delegate用于不同硬件加速,包括GPU Delegate、Edge TPU Delegate、自界说硬件Delegate(针对特定SoC厂商提供的Delegate,例如NVIDIA、Qualcomm等,使用对应的SDK和库)。竖立多线程和善存优化,确保模子和必要的数据加载到高速缓存中,减少内存拜谒蔓延。使用SoC提供的内存管制API,将模子参数预加载到片上存储器。
要领四:部署和集成到自动驾驶系统
在集成到感知模块阶段,通过数据预处理,在录像头或传感器获得的数据上进行必要的预处理,如归一化、尺寸挽救等,确保与模子输入阵势匹配。在模子推理完成后,将模子输出终结革新为实质的检测、分类或定位信息。
在实时性能测试与优化阶段,需要充分测试模子在SoC上的推理时辰、内存占用和功耗。使用SoC提供的性能监控用具,实时监测系统景象。识别影响性能的要道身分,如数据I/O、计较密集部分进行瓶颈分析。左证测试终结,挽救模子结构、量化战略、线程数等参数。以致可能需要回到模子教师和革新阶段,重新挽救和优化。
在模子加载和推理经由中,不错添加极端拿获机制,确保系统在极端情况下大致安全左迁或规复。在多样驾驶场景和环境下万古辰开动,测试系统的踏实性和可靠性。临了,通过援助OTA更新,大致辛苦更新模子和软件,以适合新场景和校正性能。