
AI评话失色真东谈主!豆包语音大模子升级长崎岖文贯通

允中 发自 凹非寺
量子位 | 公众号 QbitAI
市面上好多的语音模子如故能保证饱和当然的合成进展,但在音质、韵律、情谊,以及多扮装演绎上还有探索空间。相配是在演义演播场景下,念念要失色一流主播细巧的演播成果,要作念好旁白和扮装的分裂演绎、扮装情谊的精确抒发、不同扮装的分裂度等。
传统的演义TTS生成容颜,需要提前给对话旁白、情谊、扮装打标签,而豆包语音模子则不错作念到端到端合成,无需疏淡标签标注。
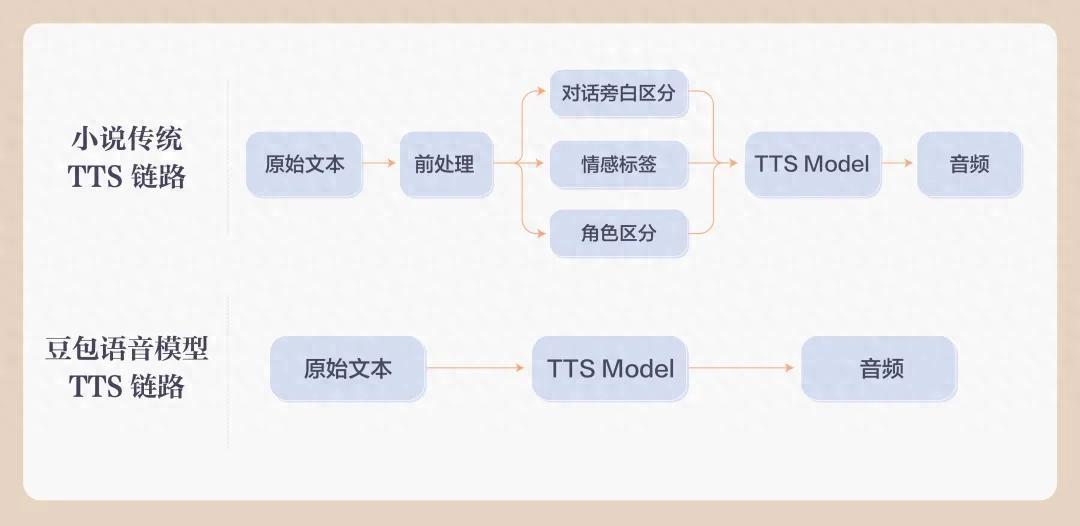
△传统语音模子和豆包语音模子合成链路的区别
矫正Seed-TTS手艺,合谚语音成果失色真东谈主原始Seed-TTS(手艺确认:https://arxiv.org/pdf/2406.02430)是一种自总结文本到语音模子,主要分为4个主要模块:Speech Tokenizer、Autoregressive Transformer、Diffusion Model、Acoustic Vocoder。
其中Speech Tokenizer阐明了参考音频信息,决定了合成音频的音色和全局格调;Autoregressive Transformer接管传入的目的文本和Speech Tokenizer的输出,进而生成出包含语义信息的Semantic Token;Diffusion Model会基于Semantic Token建模出包含语音讯息的Acoustic Token;Acoustic Vocoder厚爱将Acoustic Token重建规复出最终的音频。

△原始Seed-TTS架构
为进一步普及演义演播下的语音进展力和长文本的贯通,豆包手艺团队对Seed-TTS进行了矫正。
在数据上,演义音频作念章节级别处罚,保证了长文下的语音一致性和连贯性。在特征上,和会TTS前端提真金不怕火的音素、曲调、韵律信息和原始文本,普及发音和韵律的同期,保留演义语义。在结构上,将speech tokenizer改为speaker embedding,拔除reference audio关于语音格调的松手,因而归拢个发音东谈主能在不同扮装上作出更贴合东谈主设的演绎。临了在目的合成文本除外,疏淡加入了崎岖文的信息,从而使得模子粗略感知更大限度的语义信息,旁白和扮装音进展更精确到位。流程专科评测,优化后的豆包语音模子在演义演播场景,CMOS(Comparative Mean Opinion Score,与真东谈主打对比分的一种主不雅评分容颜)已达一流主播的90%+成果。
△优化后的豆包语音模子结构
手艺落地番茄演义,惠及听书用户豆包语音大模子团队以王明军、李满超两位演播圈大咖的声息为基础,摄取新手艺合成的千部有声书,已上线番茄演义,题材障翳了历史、悬疑、灵异、齐市、脑洞、科幻等热点书目类型。
据了解,翌日豆包语音模子会赓续探索前沿科技与业务场景的酌量,追求更极致的“听”体验。
— 完 —
量子位 QbitAI · 头条号
温存咱们,第一时辰获知前沿科技动态