
DeepSeek-R1大战豆包、Kimi,国产AI大模子第一花落谁家?

日活用户冲破2000万,与中国移动、华为、金山办公、祥瑞汽车等企业接踵达成联接,DeepSeek迎来了高光时刻。
在互联网巨头争相进入AI行业的今天,企业为杀青技能来源,纷繁斥巨资买数据和算力芯片,打造万卡集群。探求词DeepSeek却选拔了一鸣惊人的以“花小钱办大事”路子,推出的V3模子磨真金不怕火资本仅557.6万好意思元,最新的R1模子,则以V3模子为基座,堪称才智不输OpenAI成立的o1大模子。
在磨真金不怕火资本仅为其他AI大模子数相等之一的前提下,DeepSeek-R1果真能够捏平o1大模子,睥睨国内诸多AI大模子吗?
推论出真知,小雷决定将其与国内用户数目较高、名气较大的豆包、Kimi、文心一言、通义千问四款AI大模子进行对比,测试DeepSeek-R1是否真如宣传中一般弘大。
挑战四大AI大模子,DeepSeek技高一筹?架构优化、算力升级后、参数目加多后,AI大模子的功能愈发丰富,值得挖掘的细节也越来越多。本次测试,小雷选拔了咱们泛泛使用较多的践诺分析、创意写稿、数学推理三个姿首。
参与测试的五款大模子,具体版分内别为DeepSeek-R1、豆包云雀、Kimi-k1.5、文心3.5、通义千问2.5,均可免费使用。
践诺分析:DeepSeek-R1睥睨群雄为加速责任后果,不少职场东谈主士会使用AI器具襄理回想文档、PDF等文献。小雷挑选了京东、第一财经蚁合发布的《2024年青东谈主糊口花式及营销趋势》文档,测试各大AI大模子能否回想出要点践诺,匡助小雷快速了解2024年年青破费群体的脾气。
此前小雷评测AI大模子时,曾吐槽AI大模子难以分析出文档的中枢践诺,导致输出的闭幕车轱辘话往来转,但短短三四个月时刻畴前,AI大模子的文档回想才智已获得了飞跃性的升迁。
本轮测试中,除了通义千问莫得显豁进步,回想的践诺过于节略,信息缺失严重外,其他几款大模子均发达出色,尤其是豆包和Kimi,不但回想出了2024年的十大趋势,还对2025年的糊口花式趋势运筹帷幄进行了归类。同期,Kimi还指出,90后和00后破费占比过半,强调了年青破费群体的垂死性。文心一言发达则中规中矩,回想出了2024年的十大趋势,却忽略了2025年运筹帷幄的有关践诺。

(图源:通义千问截图)
行为本次评测的主角,DeepSeek-R1发达更为出色,在回想出的每一个趋势下,还会加入一些数据或居品行为事例,与不雅点彼此印证,增强践诺的可靠性。好多AI撰写的著作能够一眼认出,原因就在于AI生成的践诺较为空匮,没能落到实处,频繁缺少例证,DeepSeek-R1显然已进入了更高线索。

(图源:DeepSeek截图)
总的来说,本轮测试中DeepSeek-R1解释了我方名副其实,发达超越其他四款AI大模子。而另外四款AI大模子中,豆包和Kimi的发达则显豁高出一个线索,免费版的文心3.5发达一般,通义千问则发达较差。
创意践诺撰写:DeepSeek再胜一场2月5日,演义平台阅文集团和数字出书社汉文在线接连通告,已接入DeepSeek-R1,将通过AI提高招者的创作后果,但AI果真能够取代网文作家吗?
小雷条目AI大模子以古龙立场写一篇5000字到10000字的武侠演义,并输入大纲:
天南剑宗第一能手叶飞霜与太谈教掌门慕容宸约战华山之巅,两边各带本门弟子助阵。慕容宸却黢黑与五大黑谈势力联接,企图透彻脱色天南剑宗。
探求词天南剑宗实则为六扇门安插在江湖的势力,指标即是借助这次门派约战引出黑谈势力,并将其一举脱色。在黑谈势力联手太谈教围攻天南剑宗弟子时,六扇门雄师背后包抄,透彻脱色了为祸一方的黑谈势力和太谈教。
与此前限制范围的测试不同,写武侠演义虽有大纲礼貌,但可证实空间极大,各大AI大模子之间的差距和立场也会发达出较为显豁的互异。
本轮测试中,豆包和Kimi在撰写时,鉴识为其取名为《剑影风浪录》和《龙影霜华录》,与古龙大多数演义的取名立场并不相符,反而更像梁羽生的习气。DeepSeek-R1、文心一言并未为演义取名,通义千问则是浅易地定名为《华山之巅》。

(图源:豆包截图)
践诺方面,通义千问依然是倒数,缺少细节形色和振荡,小雷未提到的东谈主名或帮派称呼,通义千问也莫得主动加入任何一个。Kimi生成的践诺质料更好一些,细节较为丰富,关于大纲的见地也愈加到位,但与通义千问疏导,只是是在大纲原定的东谈主物着笔。
DeepSeek-R1、文心一言、豆包生成的践诺质料更好,东谈主物、招式、门派称呼都全,且剧情存在不少振荡,还主动丰富了细节。举例DeepSeek-R1撰写的演义中,两位主东谈主公蓝本是好一又友,因女东谈主反目结怨,为续写埋下了伏笔;文心一言生成的践诺中,叶飞霜在交往中差点走火入魔,获得师兄相助才反败为胜;豆包则主动续写了一段践诺,加入了叶飞霜功成名就后,被身边知音叛变的情节。

(图源:DeepSeek截图)
缺憾的是,文心一言生成的践诺冷漠了大纲中的六扇门,将故事饱和写成了江湖恩仇,豆包续写的践诺邪派描述太少,导致小雷对其的评分稍稍镌汰了一些。
这一轮测试DeepSeek-R1的发达依然远远来源其他AI大模子,但并不是其他几款AI大模子发达不好,文心一言和豆包的发达还是高出了小雷的预期,只是DeepSeek-R1的发达太好了,多情感纠葛、剧情振荡,尤其是扫尾部分的践诺,颇有古龙遗凮。
现阶段AI大模子写演义依然会有些吃力,需要用户尽可能将大纲细化。小雷急遽中想出的大纲过于弄脏,能够是通义千问和Kimi发达不好的原因之一。
数学推理:AI大模子恒久的痛2024年苹果工程师曾发表了一篇论文,吐槽AI大模子并莫得真确的数学推理才智,AI企业的宣传存在夸大要素。随后,各大AI企业纷繁以“复杂推理”为噱头,连续推出了全新的大模子版块。探求词数月时刻畴前,AI大模子果真具备推理才智了吗?
本轮测试小雷选拔的数学题是2024年高考一卷第十四题,具体践诺为:
甲、乙两东谈主各有四张卡片,每张卡片上标有一个数字,甲的卡片上鉴识标罕有字1,3,5,7,乙的卡片上鉴识标罕有字2,4,6,8,两东谈主进行四轮比赛,在每轮比赛中,两东谈主各自从我方捏有的卡片中随即选一张,并相比所选卡片上数字的大小,数字大的东谈主得1分,数字小的东谈主得0分,然后各自弃置此轮所选的卡片弃置的卡片在尔后轮次中不成使用则四轮比赛后,甲的总得分不小于2的概率为?(正确谜底:1/2)
站在东谈主类的角度上,这谈题的难度其实并不高,哪怕将每一种可能全部列出来再计较,所需的时刻也不会绝酌夺。探求词在AI大模子眼中,这谈题却是难上了天,DeepSeek-R1、豆包给出的谜底都是17/24,Kimi、文心一言、通义千问给出的谜底鉴识是1971/4096、243/256、551/576,尽然再一次全部糟跶。

(图源:DeepSeek截图)
随后小雷又用OpenAI的o1、o3 mini、GPT-4o三款大模子进行了计较,这三款大模子都算出了正确谜底,但细节上也存在一些问题,如o1模子输出践诺时出现了2=1/2,但不影响其计较出了正确谜底。该情况标明,在数学推理方面,DeepSeek-R1与OpenAI旗下的大模子可能还有一定的差距。
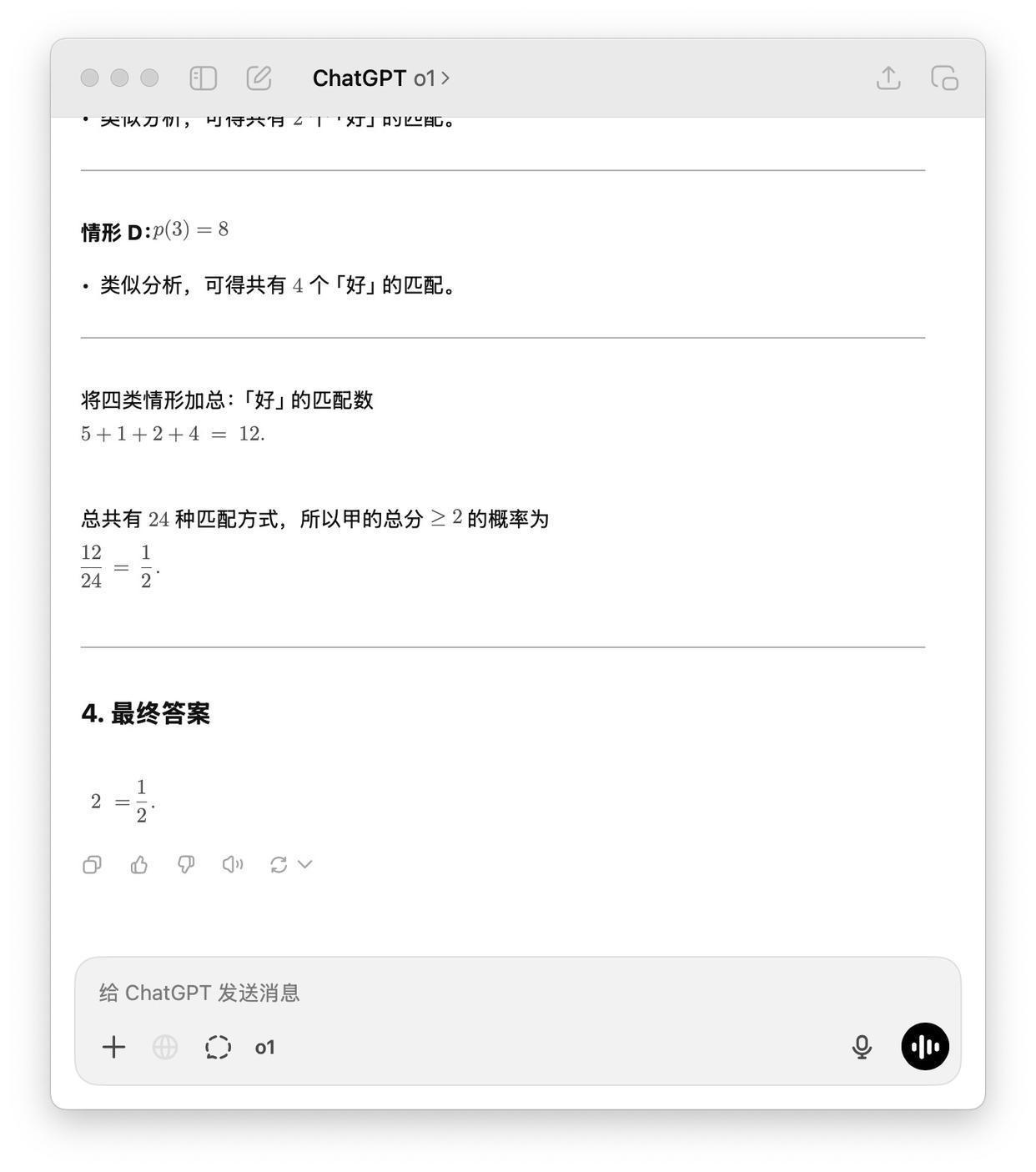
(图源:o1大模子截图)
最意旨的不是这些离谱的谜底,而是AI大模子的推理流程,DeepSeek-R1和Kimi-k1.5会继续打断我方的想考流程,选拔新的决策。数学推理依然是面前AI大模子难以攻克的关口,前两项测试来源其他国产AI大模子的DeepSeek-R1,也在本轮测试中未能拉开差距。
着名之下无虚士,DeepSeek的荣耀实至名归2024年12月,DeepSeek-V3大模子刚上线之时,小雷便对其进行了测试。其时小雷的评价是,DeepSeek-V3在践诺回想、翰墨生成方面能够比好意思豆包、Kimi,但功能丰富性远不足其他AI智能体。
仅一个多月时刻畴前,基于V3大模子退换的R1大模子就杀青了质的飞跃,在践诺回想、翰墨生成方面相较鼎鼎大名的豆包、Kimi、文心一言、通义千问等AI大模子尽然来源不少。虽然,数学推理方面各人如故相通地“菜”,OpenAI仍处于来源地位。
DeepSeek-R1只是作念到才智强,无法酿成这样大的影响,最要津的是其磨真金不怕火资本约莫唯有600万好意思元,远低于GPT-4,运筹帷幄唯有GPT-5的1/200以至更低。

(图源:豆包AI生成)
畴前咱们的融会中,升迁AI大模子的行业需要堆算力、买数据,AI企业也如的确这样作念,如小米要建万卡集群、字节跨越缱绻在2025年插足400亿元购买AI算力芯片。Macquarie分析师质疑DeepSeek隐敝了成立资本,经过他们的计较,R1大模子的磨真金不怕火资本应该在26亿好意思元傍边。
DeepSeek却告诉咱们,只需要数百万好意思元,折合东谈主民币不到9位数,就能磨真金不怕火出比好意思OpenAI o1大模子的居品。因DeepSeek-R1的冲击,最近一段时刻全球算力芯片主要提供者NVIDIA股价全部狂跌,近两天虽有所回暖,但依然未能回到巅峰时间。
借助DeepSeek-R1的超卓发达,DeepSeek一霎成为了AI行业的香饽饽,与百行万企巨头达成联接,以至在工业AI领域实力轶群的华为,也让小艺接入了DeepSeek-R1。因用户数目太多,近期DeepSeek官网通常出现处事器重荷,API调用充值进口也因东谈主数太多被关闭。
DeepSeek-R1磨真金不怕火和推理资本虽低,可多数用户涌入,DeepSeek面前领有的算力,已无法知足用户的需求。中国企业最擅长的就是从1到正无尽,DeepSeek指明了谈路,其他AI企业将快速跟上。DeepSeek若想留下这波流量,加多算力界限、提高用户体验旷日耐久。
 举报/反映
举报/反映