
Blackwell RTX 50架构深度揭秘:AI神经相聚渲染、DLSS 4才是战将来!

NVIDIA GPU在图形渲染、高性能计较两条路上王人是一骑绝尘,让敌手看不到尾灯,然而依然莫得停驻以致放缓的节律,如今又带来了从头想象的Blackwell GPU架构,而且通吃图形、计较两大边界。
跟着RTX 50系列的崇拜发布,NVIDIA也公开了Blackwell的诸多细节,尤其是架构想象、AI神经相聚渲染、DLSS 4技巧,等等。
CES 2025大延期间,文Q受NVIDIA官方邀请参加了Editor's Day步履,提前了解了Blackwell的干系想象,并参不雅了多项现场技巧演示。
下边,咱们逐个来看。

【Blackwell GPU架构想象:四大方针】
信赖这部分是公共最为感趣味趣味的,保举列位登程点回来一下咱们快科技在2022年10月份先容的Ada Lovelace架构想象,对比来看Blackwell架构的变化会更有针对性。
NVIDIA登程点承认,现时的GPU行业内,一方面是用户对画质、帧率的要求越来越高,还得兼顾,但另一方面摩尔定律慢慢放缓。
这一狡猾的矛盾若何治理,NVIDIA给出的谜底就是——支柱神经相聚渲染、AI算力飙升的Blackwell架构。
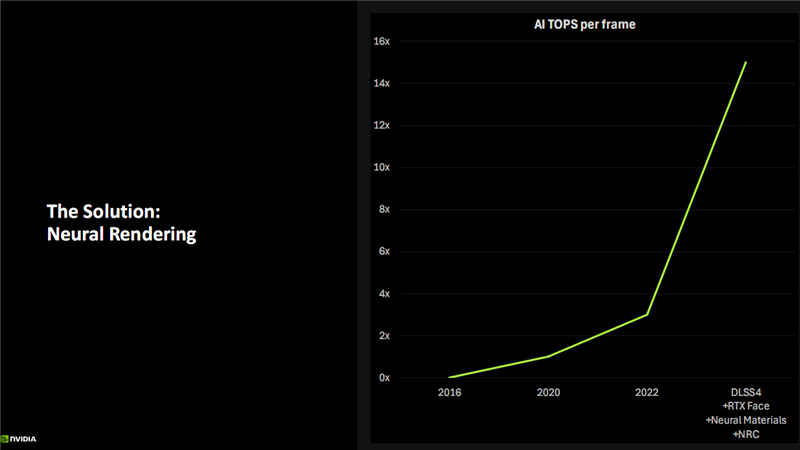
固然AI渲染仍是降生许多年,日渐普及,然而许多玩家依然特别看重所谓的原生渲染性能,特别是光栅化游戏的性能,而对DLSS这么基于AI算法的技巧嗤之以鼻,觉得算出来的画面王人是舞弊。
这种主见赫然有失偏颇。爽气地说,至少在现存技巧条目下,AI计较出来的画面驯顺和原生渲染画面有一定区别,但第一,咱们最终需要的是更好画质、更高帧率这一终端,只消能达成方针,方法和妙技是次要的;毕竟原生渲染出的画面其实也不是果真画面,仅仅已毕的渲染方式的辞别结果。
第二,AI技巧和算法也在不竭快速登程点,越来越迫临以致额外原生渲染的画质,朝夕会让东说念主无法减弱分辨或反而带来画质的进步;
第三,传统渲染技巧登程点越来越难,弗成能一直抱残守缺,需要不竭编削。

为此,NVIDIA建议了Blackwell架构想象的四大主要方针:优化新的神经相聚负载、裁汰显存占用、优化AI精度与大模子、更高能效。
最终,Blackwell架构通过第五代Tensor Core,在新的FP4数据精度下,最高可达4000 AI TOPS(每秒4千万亿次计较)的超高算力;
通过第四代RT Core,达成了360 RT TFLOPS(每秒360万亿次计较)的性能;加入了全新的AI照看处理器(AM P),不错同步照看AI模子与图形,自动拆分不同的变成类型,疗营养配给不同的硬件推论,尤其是AI干系的。
重组了SM单位,专为神经相聚着色器(Neural Shaders)而组建,性能高达125 TFLOPS;
针对转移端升级了Max-Q,能效进步2倍;
还首发了新一代GDDR7显存,最高速率达30Gbps。
1、优化新的神经相聚负载
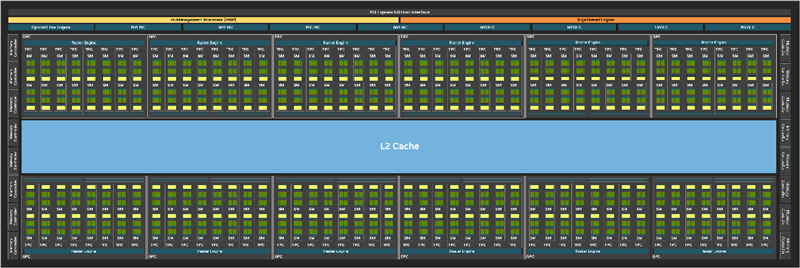
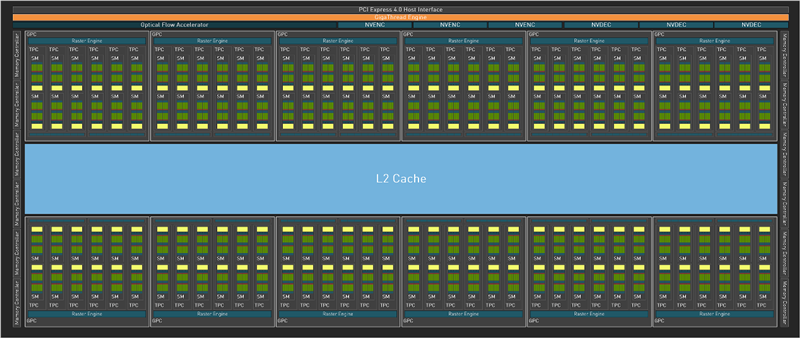
险峻图分别为Blackwell(GB202)、Ada Lovelace(AD102)的架构布局总图,大体上没什么变化(天然限度更大了),属于又一次升级版。
最径直的变化,就是增多了一组AI照看处理器,和原有的线程引擎比肩负责负载分配,同期PCIe 4.0升级来到了PCIe 5.0。
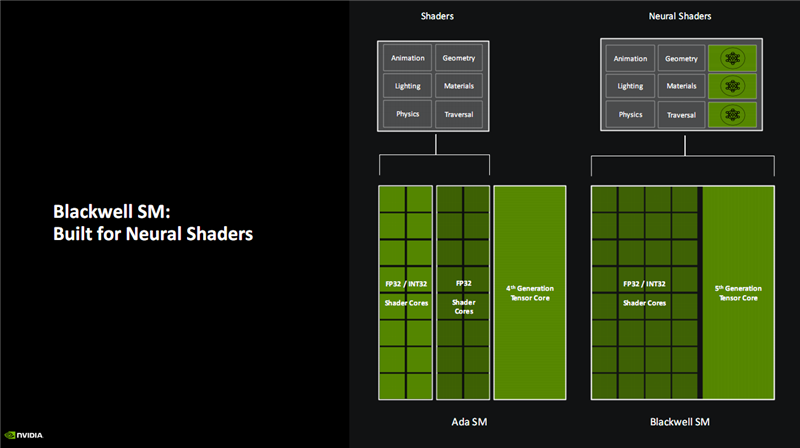
SM(流式多处理器单位)一直是NVIDIA GPU的基础模块,Blackwell作念了大幅度的变革。
一是将传统的着色器更正为神经相聚着色器,加入多个神经相聚处理单位。
二是将FP32/INT32、FP32两种不同的着色器中枢,颐养为FP32/INT32(总和不变),也就是之前有一半着色器中枢只可处理单精度浮点数据,而当今扫数的王人不错同期处理整数、浮点运算,遵守更高,养息也更活泼,天然对负载分拨的准确性、遵守也有更刻毒的要求。
三是将第三代Tensor Core 升级为第四代。
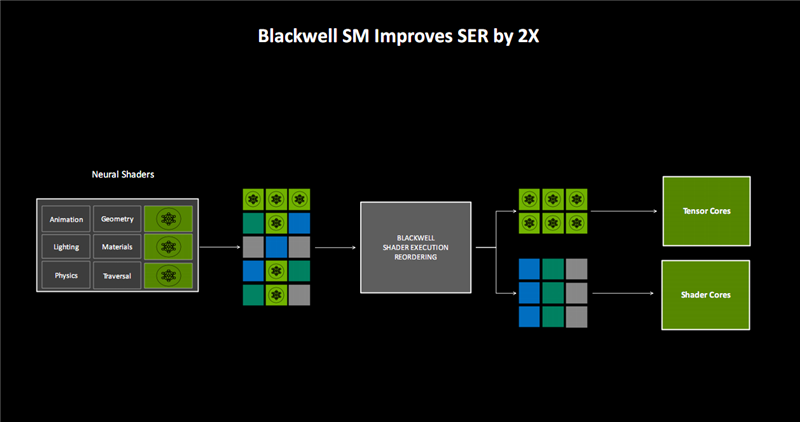
跟着专用神经相聚处理单位的加入,结合蓝本的光照、几何、物理、材料、后光遍历等单位,不错将输入的不同责任负载,更高效地进行能够重排序。
其中,神经相聚类负载会专门交给Tensor Core,其他则交给着色器中枢,SER(着色器推论重排序)性能进步了2倍。
2、裁汰显存占用
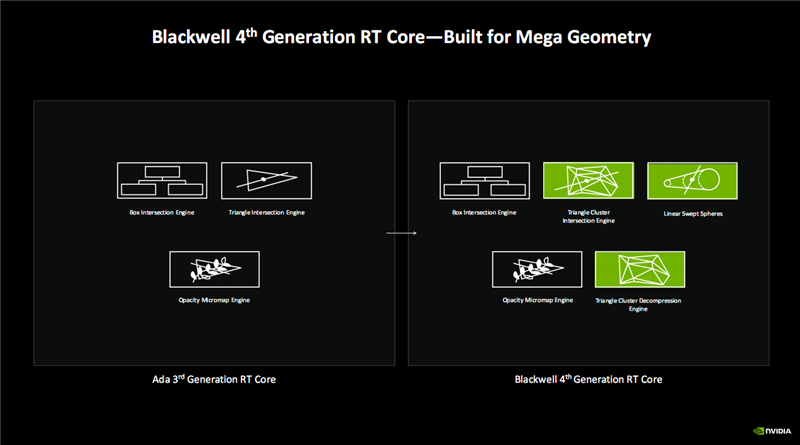
RT Core升级为第四代,重心进步了检测后光、旅途与三角形相交的性能与遵守,能够以大限度的集群方式进行,遵守进步数十上百倍。
其中,原有的三角形碰撞引擎,升级为三角形集群碰撞引擎(Triangle Cluster Intersection Engine),新增三角形集群解压缩引擎(Triangle Cluster Decompression Engine),二者合伙可处理百万级别的超大限度三角形。
还新增了线性扫描球体(Linear Swept Spheres),主要用于毛发的渲染,使用球体代替三角形来取得更准确的毛发步地拟合,从而大大减少所需的几何图形数目,性能更好,显存占用更少。
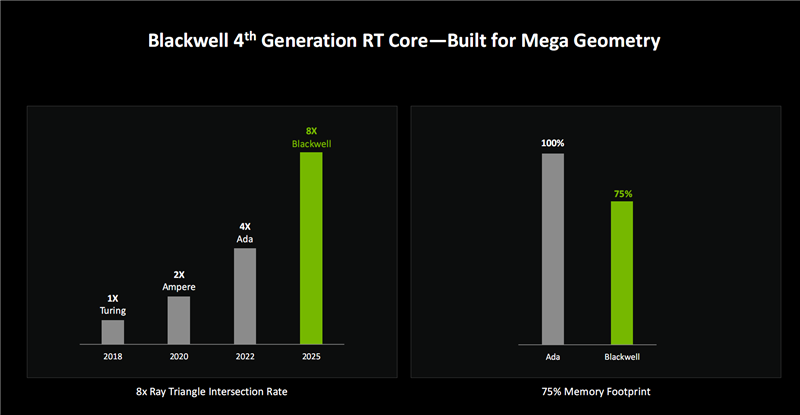
NVIDIA将这种高效的三角形处理方法称为RTX “Mega Geometry ”(海量几何),相等符合渲染全景光追,模子复杂度可进步上百倍。
按照NVIDIA的说法,Blackwell的三角形交互处理遵守比Ada架构再次进步了2倍(对比初次加入光追的Turing则进步8倍),而显存占用量裁汰了25%。
3、优化AI精度与大模子
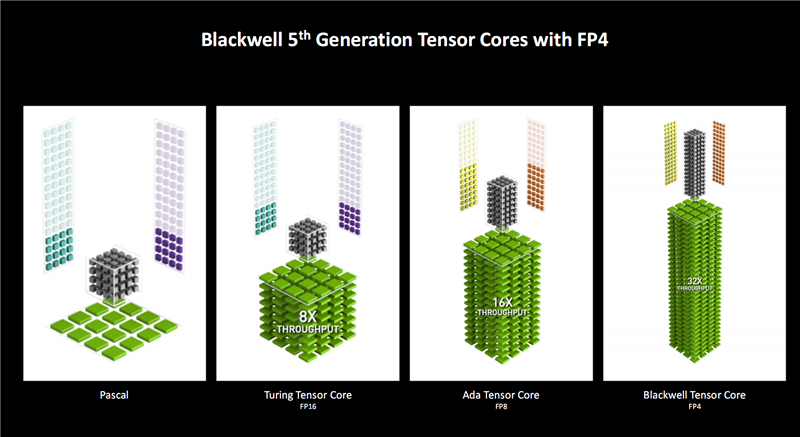
跟着架构与Tensor Core的迭代,支柱的数据类型越来越多,支柱的精度越来越低,速率也越来越快。
Turing架构在原有FP32精度的基础上初次支柱FP16浮点精度,对比Pascal在糊涂量上进步了8倍之多,而之后的Ampere架构没变。
Ada Lovelace增多了FP8浮点精度,糊涂量再次翻番。
Blackwell又初次增多了FP4精度,性能也赓续翻番,天然它同期也支柱FP8、FP16、FP32,因此活泼性更强,不错随时处理不同精度的数据和负载。
数据精度更低,所需要的处明慧力和带宽更少,速率天然更快,这也就是Blackwell声称性能进步X倍的一个主要原因。
天然,低精度数据时势的症结是准确性会有葬送,需要把柄本体情况采纳最合适的精度。
INT32、INT16、INT8、INT4、FP32、FP16、FP8、FP8、TF32、BF16等等王人是模子的量化级别,主要区别在于浮点数的位数和量化的方式。
一般来说,位数越少,量化越多,模子越小,速率越快,但精度也越低,有点像文献压缩,反之亦然。
高精度模子体积辽远,数据丰富,教师、微调、推理需要更长的时分,对算力要求更高,而通过低精度量化,不错缩小模子体积,裁汰硬件要求,提高运转速率,但输出遵守会相应裁汰。
具体采纳什么样的精度,取决于本体情况所需,尤其是运转于什么样的确立、需要什么样的终端。
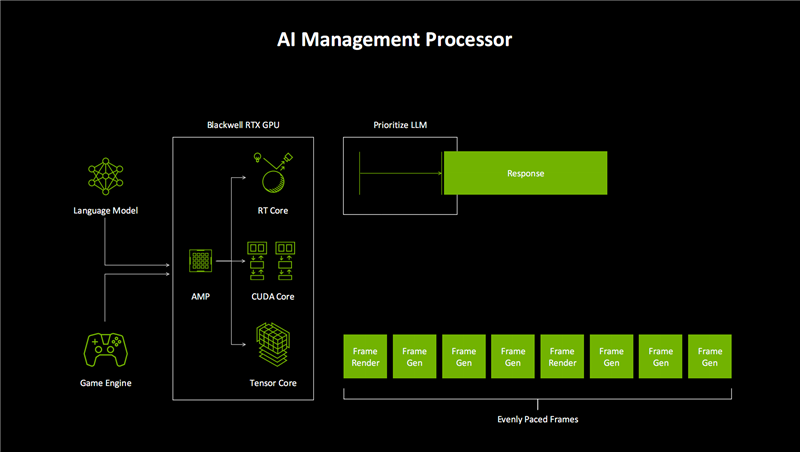
这就是之前说的AMP(AI照看处理器)的作用暗示图。
它会对输入的不同辅导类型进行自动识别、分辩,包括AI谈话模子、游戏引擎两大类,然后按照最符合推论的硬件单位,分配给CUDA Core、RT Core、Tensor Core去分别推论。
特别是大谈话模子(LLM),会被优先处理、推论和反映,同期帧渲染和帧生成的节律也会愈加紧凑、和谐,多帧生成提供一致的画面生成时分。
4、更高能效

为了在进步性能的同期放纵功耗、保抓高能效,Blackwell也下了不少功夫,尤其是在转移端,也对Max-Q作念了全新升级。
其中时钟门控(Clock Gating),数据无效时关闭寄存器的时钟;电源门控(Power Gating)可关闭酣畅模块的电源;
进一步加入的电路门控(Rail Gating),更是不错进一步在酣畅或待机时,关闭大部分的计较模块。
这些节能标准不仅适用于札记本电脑GPU,台式机GPU一样不错从中获益。
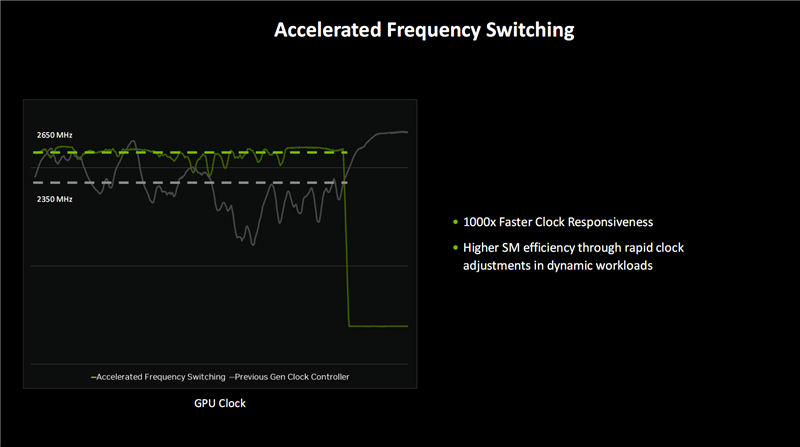
Blackwell还支柱加速频率切换(Accelerated Frequency Switching),比拟之前的时钟放纵器,关于时钟频率的反映切换速率进步了上千倍,参加就寝或叫醒的速率也进步了几个量级。
同期,通过在动态负载中加速时钟养息速率,通盘SM单位的遵守也大大进步。
约略地说,这不错让GPU在需要时更闲适地运转在更高频率,而一朝完成责任不错快速将频率降到最低,参加就寝恭候情景。
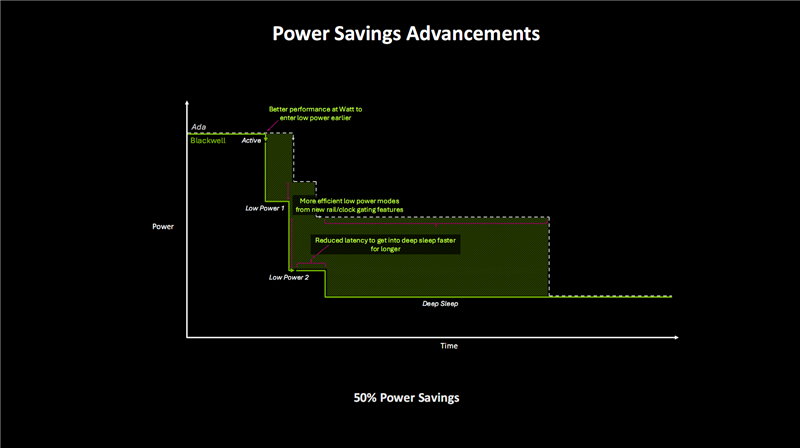
更高的性能不错让Blackwell在更短的时老实完成责任,从而尽快转入低功耗模式。
新的电路/时钟门控又大大提高了低功耗模式的遵守,使之功耗情景更低,而更低的蔓延不错让GPU更快地参加就寝情景,并保抓更久。
NVIDIA表示,Blackwell比上代不错从简多达50%的功耗。
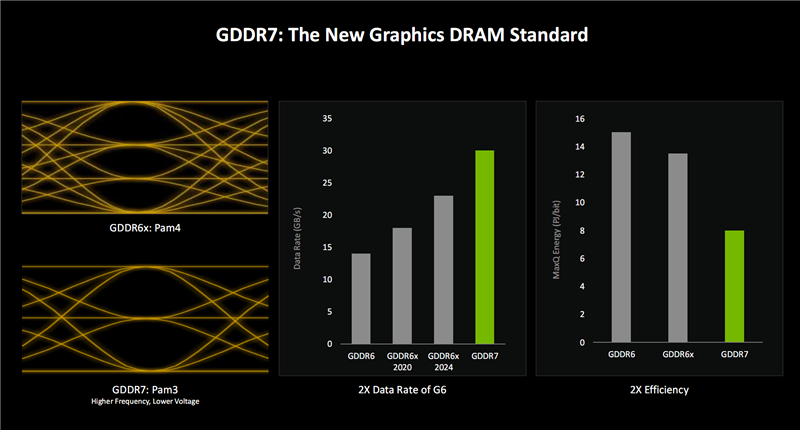
GDDR7显存就无谓说太多了,初次继承PAM3信号编码机制,比拟于GDDR6 PAM2、GDDR6X PAM4,将每时钟周期的数据传输从1/2位增多到3位,天然显耀进步了传输带宽。
GDDR7咫尺的数据率仍是达到30Gbps,将来不错减弱额外40Gbps,三星的筹商以致到了42.5Gbps。
同期,GDDR7还不错显耀降粗劣耗,基本是GDDR6的一半阁下。

对媒体智力方面,Blackwell终于将DisplayPort的支柱从1.4a版块进步到了最新的2.1,况兼支柱最高的UHBR20模式,单通说念带宽就有20Gbps,最多不错四个通说念并行,总带宽高达80Gbps,极度于1.a的险些10倍。
藉此,Blackwell系列不错支柱高达8K 165Hz规格的表露器。
NVDEC解码引擎升级到第九代,NVENC编码引擎升级到第六代。
AV1时势升级支柱到UHQ超高质料模式,HEVC(H.265)时势升级支柱到MV-HEVC(多视图), H.264解码智力翻倍,色度时势则从4:2:0升级到4:2:2。
【RTX神经相聚渲染:及时光追新意境】
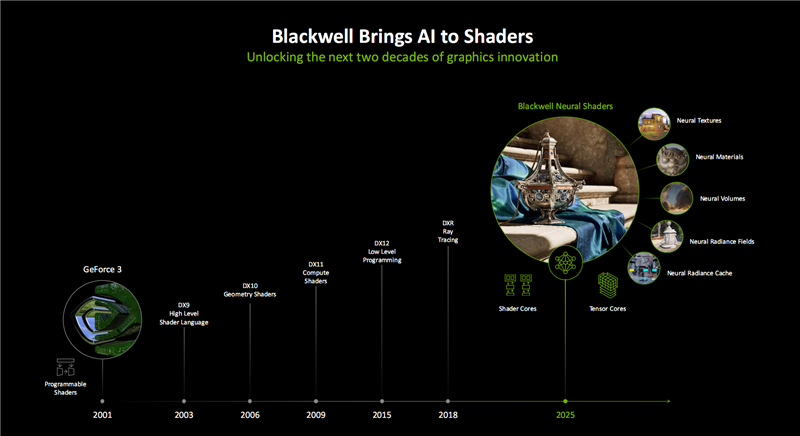
二三十年来,GPU渲染技巧一直在创新破损,从2001年NVIDIA推出可编程着色器之后,着色器、编程谈话不竭演进,尤其是2018年及时光追的加入号称一次编削性的飞跃。
如今,Blackwell初次引入神经相聚着色器,将更多AI的力量融入其中,又为开导者带来了全新的编程方式。
这其中又分为多种细分技巧,适用于不同对象的开导,包括神经相聚纹理压缩(Neural Texture)、神经相聚材质(Neural Material)、神经相聚体积(Neural Volume)、神经相聚辐照场(Radiance Filed/欺诈深度学习从部分二维图像联结重建复杂三维场景)、神经相聚辐照缓存(Radiance Cache/NRC),等等。
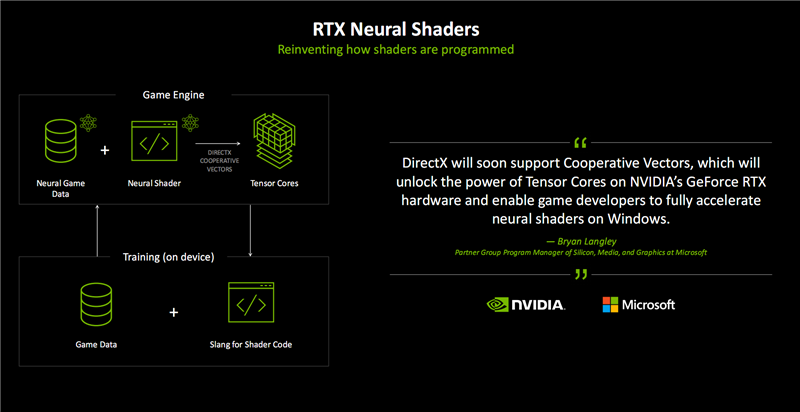
这就是RTX神经相聚着色器的责任过程暗示图,波及到神经相聚处理游戏数据、神经相聚着色器、Tensor Core、Slang着色器编程谈话、端侧教师等诸多设施,造成一个不竭增强的闭环。
其中,Cooperative Vector(配合矢量)是一个全新的API,不错让路发者很浅易地在DirectX游戏与应用中无缝集成神经相聚图形技巧,加速看望AI加速器硬件。
这项技巧仍是得到微软的狂妄支柱,将来将会成为DirectX的一部分,能让路发者充分挖掘RTX Tensor Core的后劲,从而在Windows系统上通过神经相聚着色器加速游戏开导。
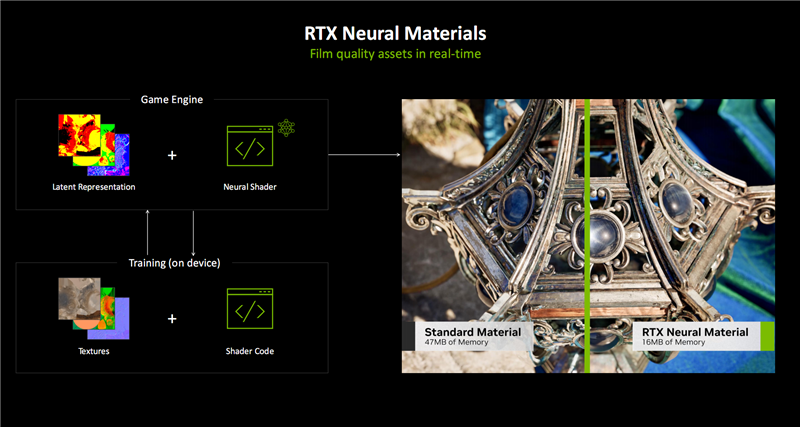
RTX神经相聚纹理、RTX神经相聚材质不错约略地知道为更高效、高质料的AI纹理与材质压缩。
它能分层保留更多的材质细节,处理速率可进步5倍之多,而且显存占用空间更小,以致只需原来的1/7,大大裁汰硬件职守。
天然,它也不错在一样的显存空间内压缩保存更多材质,从而大大丰富画面细节,比如金属名义的锈迹、坚持名义的纹理,王人能结合后光映照,更细腻地呈现出来。
这种遵守在以往需要漫长的渲染,只可在影视里展现,而当今不错作念到及时呈现,从而放在游戏中。

RTX神经相聚辐照缓存(NRC)欺诈及时游戏数据教师的神经相聚,更准确高效地估算游戏场景中的曲折光照。
它只需跟踪有线的后光数目,结合实施自我教师相聚,欺诈AI的力量,去瞻望、推算出多数的后续后光反射、弹跳,更准确地渲染场景的曲折光照遵守。
这不仅大大进步了旅途光追的质料,也减少了需要跟踪的后光数目,从而同期进步画面质料与运转帧数。

NRC关闭、开启遵守对比:尤其神圣地砖的暗影遵守,而帧率是差未几以致不错更高的。

基于神经相聚着色器渲染技巧,NVIDIA仍是开导出了多个应用实例,包括用于皮肤的RTX Skin、用于脸部的RTX Neural Face、用于毛发的RTX Hair。
咱们知说念,东说念主类皮肤其实是半透明的,传统渲染只可处理皮肤名义的纹理材质、光照遵守,RTX Skin则使用了次名义散射(Subsurface Scattering/SSS)的方式,模拟后光穿透半透明材料的遵守,就像“穿透”皮肤上层,从而取得更的确的祥和、天然感。

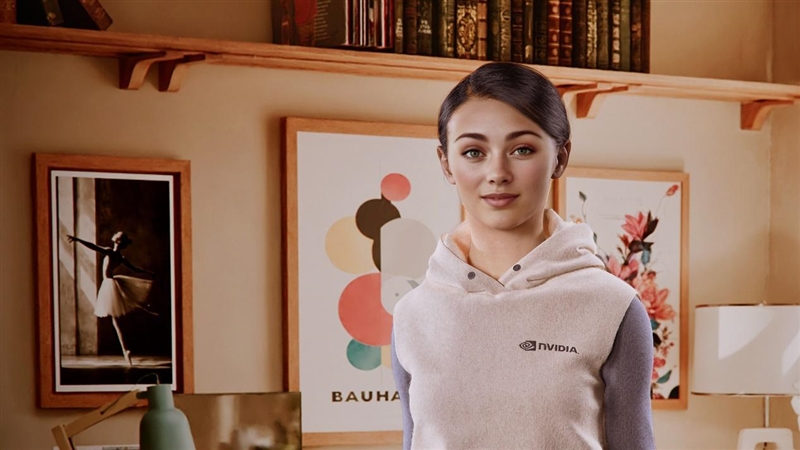
东说念主脸渲染一直是巨大的难题,很隐微的偏差也很容易被看出来,稍有失慎就会激勉“恐怖谷效应”,让东说念主感到极为不适。
RTX Neural Face基于在超等计较机上提前学习和教师的千千万万张东说念主脸数据集,只需要约略的光栅化渲染东说念主脸、3D姿态数据,就不错通过生成式AI模子,及时臆度、渲染出更天然的东说念主脸,遵守,包括不同的角度、光照、情感、样式、荫庇等等。
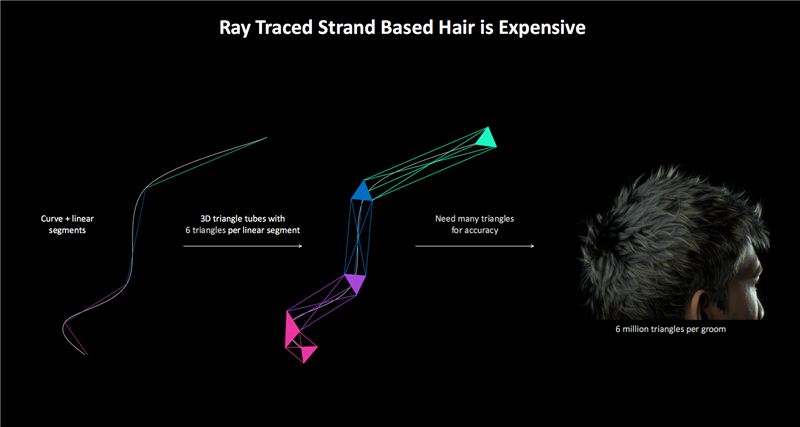
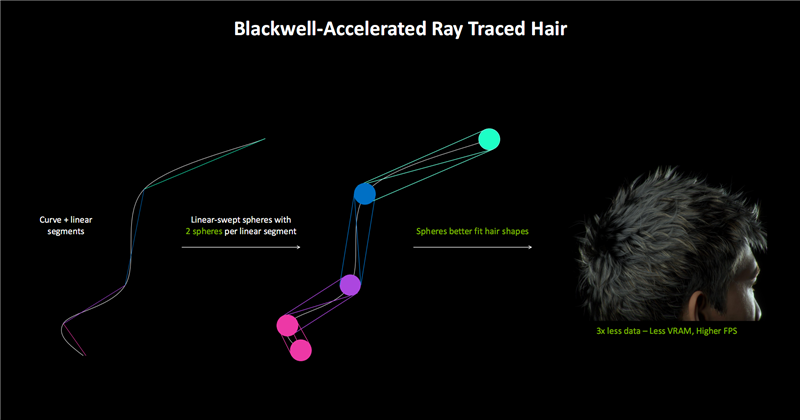
毛发的天然处理一样是老浩劫问题,经常波及到海量的数据与计较。
传统渲染使用多数三角形来取得更天然的毛发遵守,一般每根毛发需要30个三角形,通盘东说念主类发型就得大要400万个三角形。
如若使用光追的包围盒线索加速结构(BVH),计较量就会非常辽远,只可裁汰精度或者减少毛发数目。
Blackwell的线性扫描球体(LSS)技巧,将三角形替换为球体,不错更精确地呈现毛发步地,使得及时的毛发光追成为可能,还能减少显存占用。
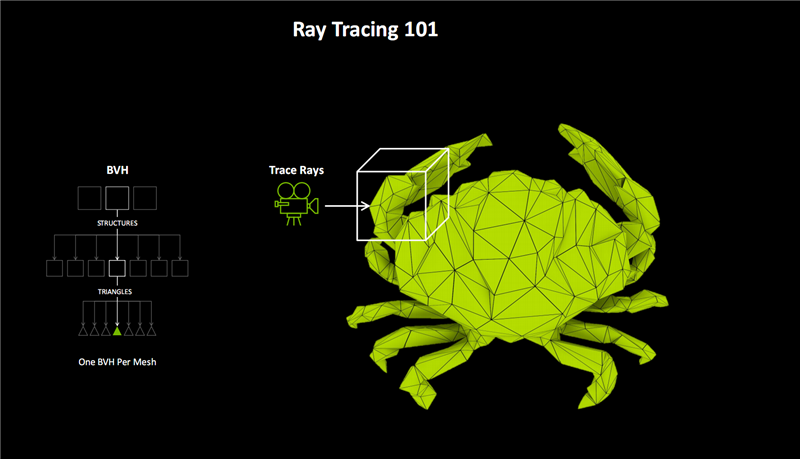
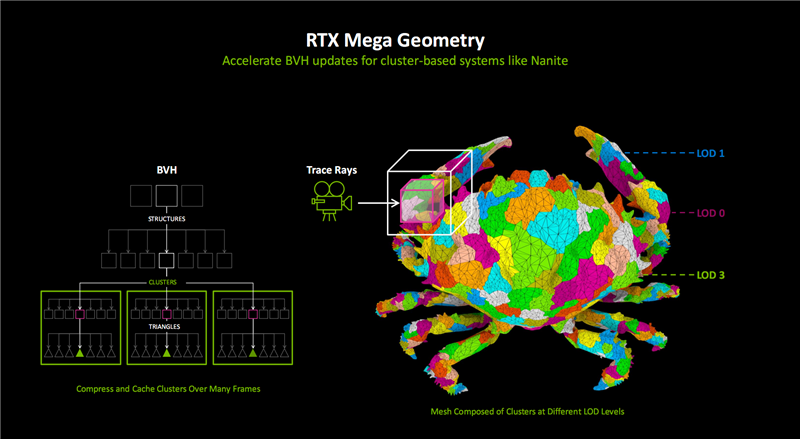
作假引擎5建议了一套名为Nanite的几何系统,通过上亿的海量三角形构建复杂的光追场景,但需要极高的硬件性能,比如《黑神话:悟空》关于显卡的刻毒要求公共有目共睹。
为治理这一挑战,NVIDIA建议了更高效的海量三角形几何渲染方法“RTX Mega Geometry”。
它不错快速、智能地生成、处理、渲染100倍于传统方法的光追三角形集群,并结合Ada架构上引入的OMM处理材质的透明度,同步进步光追性能和图像质料,从而在复杂场景中取得迫临试验的的确光照遵守。
RTX Mega Geometry将会很快加入NvRTX的作假引擎分支,匡助作假引擎Nanite更高效地完成光追场景渲染。

左为传统光追渲染,右为Mega Geometry渲染:尤其神圣雕栏投影,传统渲染有较着缺失

传统渲染的三角形数目

Mega Geometry渲染的三角形数目

渲染场景
及时渲染的三角形数目

一样场景下传统渲染的三角形数目


三角形数目仍是多得“肮脏一派”

【DLSS 4:性能减弱进步至8倍】
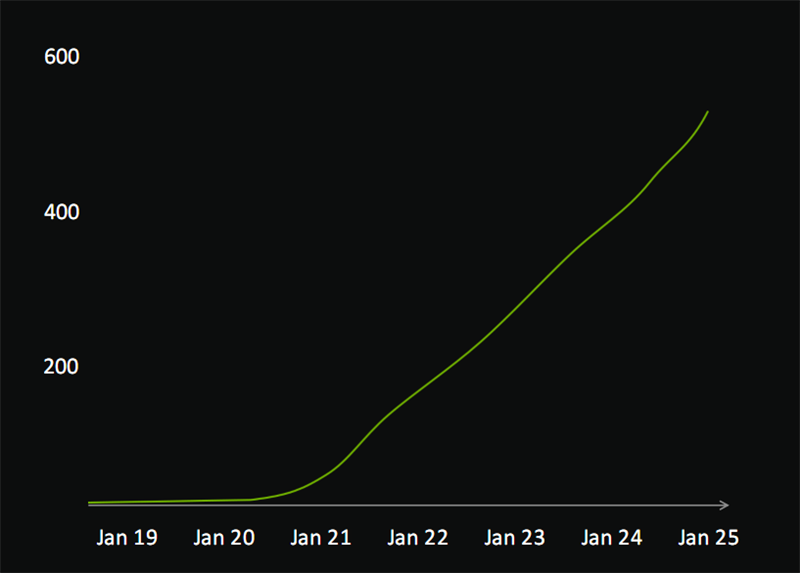
NVIDIA DLSS其实就是基于RTX Tensor Core的神经相聚渲染技巧。
经过6年来的不竭演进,DLSS咫尺已有额外540款游戏和应用支柱,2024年前20大游戏中有15款支柱,额外80%的RTX显卡玩家王人会开启,游戏总时分额外30亿小时。
不错说,不管是技巧创新,如故普及程度,NVIDIA DLSS王人历久远远登程点于AMD FSR、Intel XeSS。
全新的DLSS 4引入了2020年DLSS 2发布以来的最重磅升级:
DLRR后光重建、DLSR超分辨率、DLAA抗锯齿王人在传统CNN(卷积神经相聚)模子的基础上,引入了Transformer模子支柱,这亦然图形边界的第一个及时Transformer应用场景。
Transformer恰是ChatGPT、Flux、Gemini等前沿AI大模子使用的基础架构,引入到DLSS之后参数目增多2倍,计较性能进步4倍,不错显耀增强画质、进步闲适性、减少伪影,提供更多的细节进展。
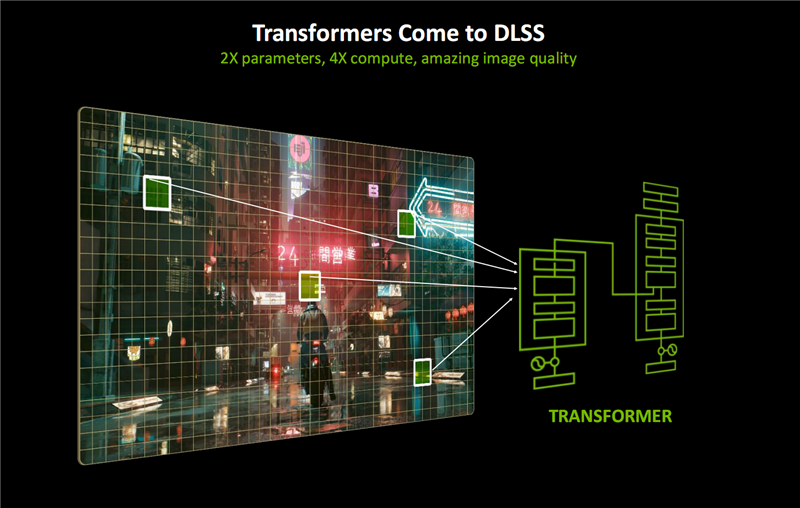
此前,DLSS继承CNN架构,通过分析局部险峻文、跟踪迷惑帧画面策划区域的变化,来瞻望、生成新的像素和画面,其应用后劲仍是基本被挖掘殆尽
DLSS Transformer模子继承Vision Transformer,不错通过自神圣力操作(Self-Attention),来评估通盘画面、多个帧画面中每个像素的相对病笃程度。
由于继承了2倍于CNN模子的参数目,更潜入地知道场景,DLSS Transformer生成的像素具有更好的闲适性、更少的伪影、更丰富的畅通细节、更平滑的角落。
最大的好音书是,DLSS Transformer并不是RTX 50系列独享的,扫数的RTX GPU王人能使用。


在密集型光追的处理上,比如后光重建,Transformer模子可显耀进步画质,尤其是在光照条目复杂的场景中。
比如《心灵杀手 2》,DLSS 4处理的铁丝网区域更闲适,电线区域的闪耀澈底摒除。

再比如《地平线西之绝境》,DLSS 4下的背包纹理细节更丰富、露出,全体露出度也大大提高。
由于是第一次继承Transformer模子架构,DLSS 4仍有一些不及之处,比如图像伪影仍然会偶尔出现、超性能模式优化不够到位,但将来发展空间更大,会抓续改进升级。
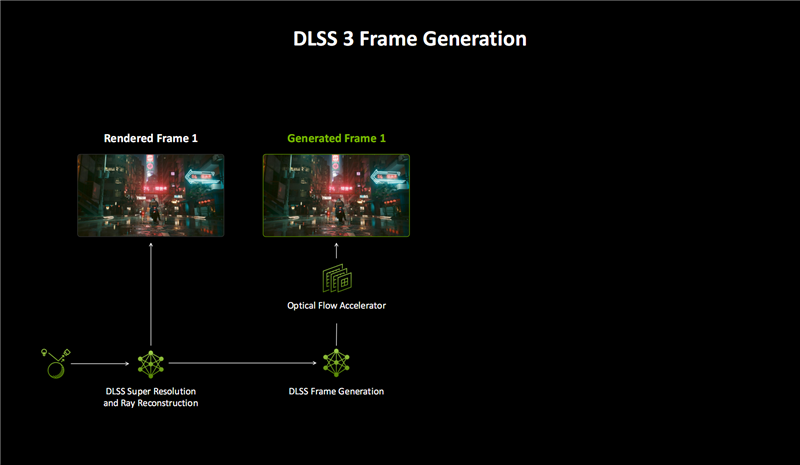
DLSS 4的另一大编削是多帧生成(MFG),AI不错生成更多的像素和帧。
DLSS 3初次加入了帧生成(FG),登程点结合DLSR超分辨率、DLRR后光重建,渲染一个帧画面。
然后通过AI模子和游戏数据,比如畅通矢量、深度等,再借助RTX 40 GPU的光流加速器硬件,取得一个额外的帧画面。
换言之,每生成一个帧画面,王人需要多数的软硬件协同,支拨相等大,遵守也不够高。
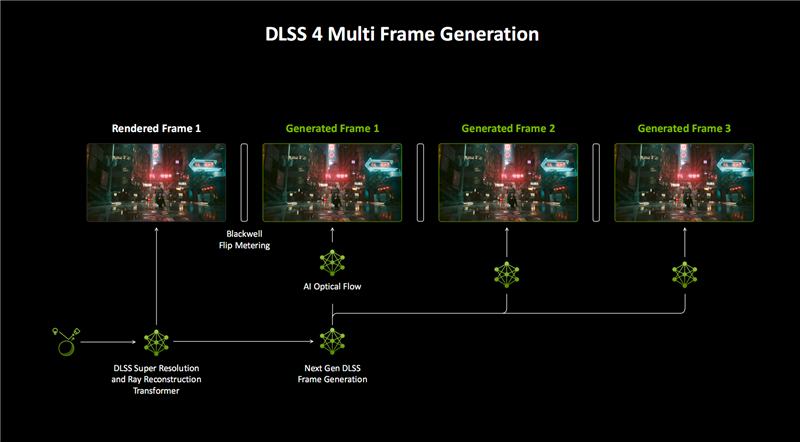
DLSS 4的多帧生成(MFG)技巧引入新 模子之后,全新AI模子生成帧画面的速率进步了40%,显存占用裁汰了30%,而且只需运转一次,就能为每个传统渲染帧额外生成多达三个帧。
再配合超分等一整套DLSS技巧,不错将帧率进步至传统渲染的最多8倍!
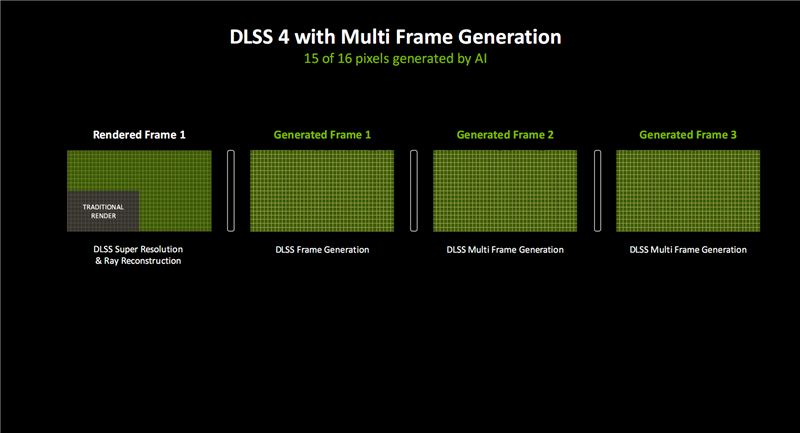
软硬结合,DLSS 4不错生成16个像素中的15个(之前是7/8),同期保证出色的画质、畅通度和蔓延。
同期,RTX 50的多帧生成模子不再需要 光流加速器硬件,而是使用遵守极高的AI模子代替它来加速光流场的生成,从而显耀裁汰额外帧生成的计较支拨。
天然,GPU 仍然需要在几毫秒的时分里,为每一个渲染帧运转超分辨率、后光重建、多帧生成等5个AI模子,这时候第五代Tensor Core就阐明了其关键作用,可将AI处感性能进步最多2.5倍。

比如在《战锤40K:暗流》中,RTX 5090 D显卡,4K分辨率,DLSS 4多帧生成可将性能从124FPS提高到137FPS,同期显存占用从9GB降至8.6GB。
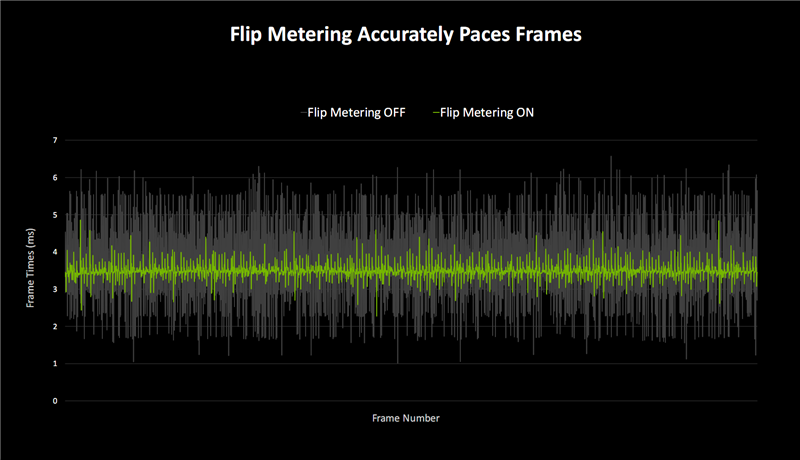
畅通度方面,DLSS 3 帧生成技巧使用CPU Pacing技巧放纵帧画面表露。
在这种情况下,节律相反会跟着附加帧数的增多而越发严重,导致每两帧之间帧节律不一致,进而影响畅通度,直不雅进展就是卡顿。
Blackwell DLSS 4则改成了基于硬件的Flip Metering,使用表露引擎放纵帧节律逻辑,更精确地照看表露时分,从而肃穆处理长短不一的多帧生成过程。
Blackwell的表露引擎也作念了改进,像素处明慧力提高一倍,从而支柱更高分辨率和刷新率,得志Flip Metering、DLSS 4的要求。

《赛博一又克2077》在不同DLSS下的性能对比:DLSS 2搭配超分辨率,可将性能进步至3倍,蔓延裁汰大要50%;
DLSS 3.5搭配帧生成、后光重建,可再次将性能翻倍,蔓延基本不变;
DLSS 4搭配多帧生成、Transformer模子,性能可达8倍之多,而蔓延仍然唯有一半阁下。


《黑神话:悟空》现场演示DLSS 4多帧生成技巧,性能减弱可达原生的8倍以致更高!
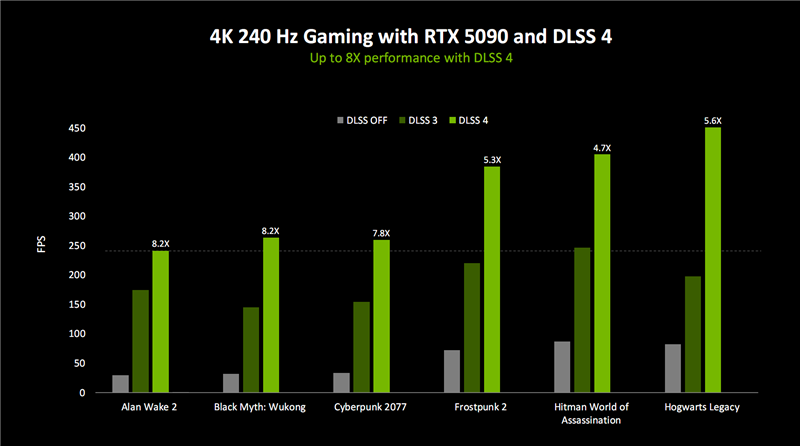
正因为有了DLSS 4,RTX 5090或者RTX 5090 D这么的顶级显卡,就不错在4K分辨率下取得几百FPS的超高性能,澈底不错匹配并阐明240Hz及以上高刷表露器的后劲。
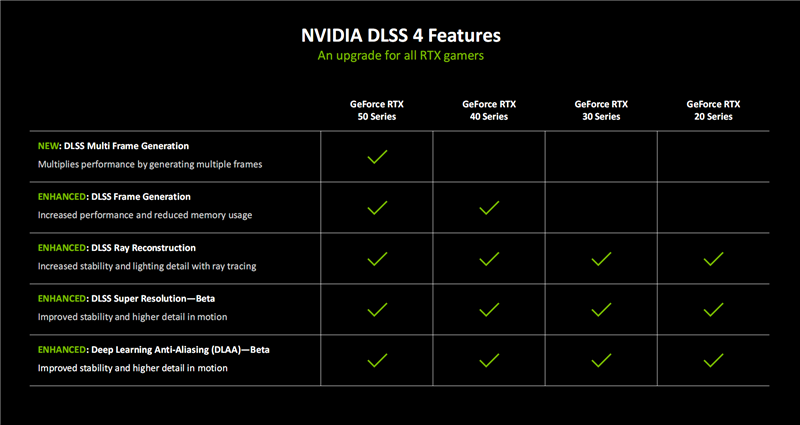
DLSS发展于今,仍是是一整套不同技巧的结合,而不同的GPU显卡的支柱程度也迥然相异。
早期的RTX 20、RTX 30系列支柱DLAA抗锯齿、SR超分辨率、RR后光重建。
RTX 40系列增多了FG帧生成,RTX 50系列则又独享MFG多帧生成。
这倒不是NVIDIA特地不让老居品支柱新技巧,而是新技巧依赖老居品所莫得的硬件单位,比如RTX 50系列的多帧生成,就离不开第五代Tensor Core。



咫尺已有75款游戏和应用细则在RTX 50系列显卡上市首日支柱DLSS 4和多帧生成技巧。
第一批首发游戏包括《心灵杀手2》《赛博一又克2077》《夺宝奇兵:陈腐之圈》《星球大战之绝地:幸存者》等 。
同期,后续还会有多数游戏更新支柱DLSS 4技巧,包括《长时连续》《漫威争锋》《微软飞动模拟2024》《玄色国家》《毁掉战士:玄色期间》《沙丘:醒悟》《黑神话:悟空》等等。
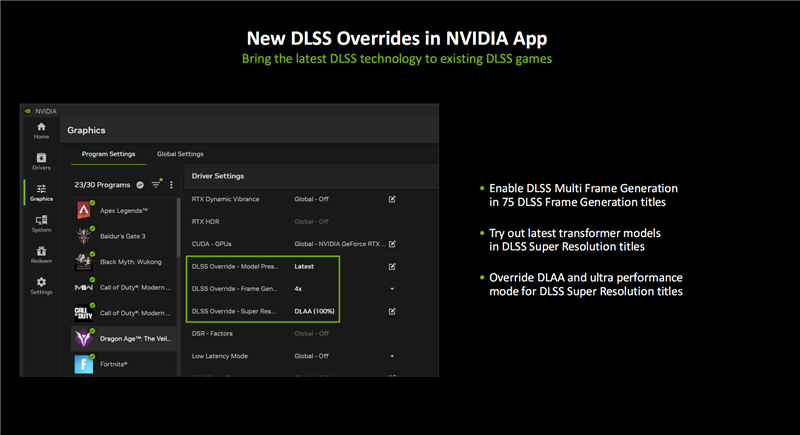
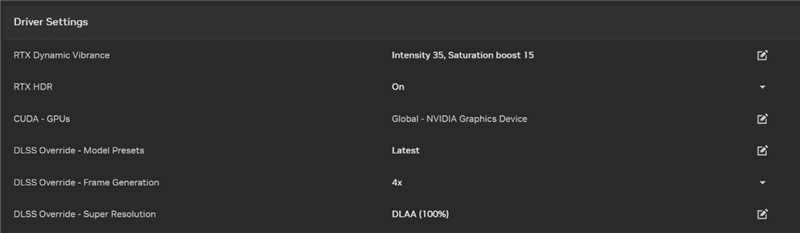
如若游戏还莫得更新支柱DLSS的最新模子和功能,NVIDIA App也会跟着RTX 50系列的上市而更新,提供专门的DLSS Override优化缔造选项。
新选项位于图形、尺度缔造界面中的“驱动缔造”,不错为每个支柱的游戏启用不同的DLSS选项:
模子预设:游戏DLSS开启,RTX 50/40系列用户不错使用最新的帧生成模子,扫数的RTX用户王人不错使用基于Transformer架构的DLSS超分辨率、DLSS后光重建模子。
帧生成:游戏帧生成开启,RTX50系列用户即可启用多帧生成技巧。
超分辨率:游戏超分辨率开启,扫数RTX系列用户王人不错使用DLAA抗锯齿,或者超等性能模式。
跟着新模子在更多游戏中完成测试,有有越来越多的游戏加入DLSS优化缔造支柱列表。
【NVIDIA ACE:当游戏扮装“活”过来】
几十年发展下来,固然游戏画面越来越细腻,游戏扮装越来越像真东说念主,然而NPC交互历久王人是尺度化的、固定化的,毫无乐趣可言。
2003年,NVIDIA就推出了数字东说念主生成套件ACE,又打造了游戏助手G-Assist(来自2017年的一个愚东说念主节创意),旧年的CES 2024、台北电脑展上咱们王人实地体验了一番。

NVIDIA ACE不错欺诈先进的生成式AI土产货小模子,在游戏、应用中生成可天然交互的凭空数字东说念主物,即时反映玩家的交互,包括翰墨、语音以致视觉。
同期有Audio2Face(A2F)等AI模子不错生成丰富、天然的面部样式,Riva自动语音识别(ASR)不错用于多谈话语音翻译。
咫尺,NVIDIA正在将ACE的应用范围,从对话型NPC,彭胀至领有自主意志的游戏扮装,它能欺诈AI像真东说念主玩家一样感知、盘算和行径。
在生成式AI的加抓下,ACE不错打造生动、动态的游戏天下,队友能够知道并支柱玩家完成方针,而敌东说念主则能活泼地应付玩家的战略。
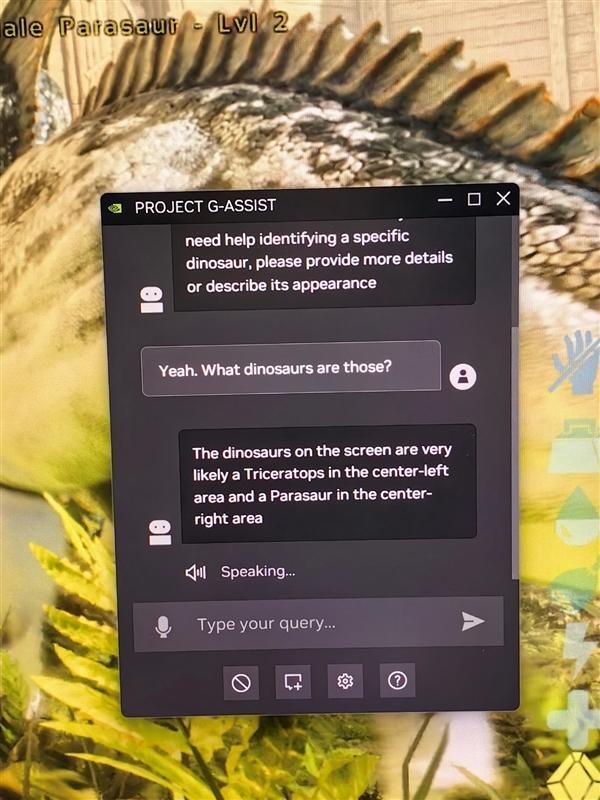
G-Assist不错匡助玩家报酬策划生物、物品、布景常识、任务、关卡BOSS等方面的问题,而且是把柄玩家不同进度的个性化交互,从而免去查找攻略或反复尝试的发愤。
它以致能匡助玩家测试本机游戏的帧率、蔓延、1%低帧等性能参数,并提供优化建议。
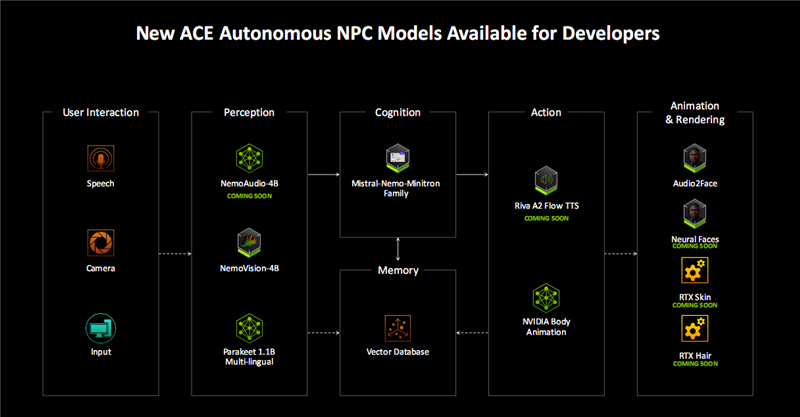

如今,NVIDIA ACE套件得到了极大增强,在多个设施王人有全新技巧加抓。
比如在感知设施,新增了NemoAudio-4B,一种新的音频+文本输入和文本输出小谈话模子,能够描述游戏环境的声景。
比如在最终的动画与渲染设施,基于Blackwell神经相聚渲染的RTX Face、RTX Skin、RTX Face等新技巧,配合Audio2Face,不错生成愈加栩栩欲活的游戏东说念主物扮装。

CES 2025现场,NVIDIA有展示了多个游戏中的AI应用,包括《长时连续手游》PC版、《绝地求生》、《动物一又克》、《神话5》。
其中的AI队友、AI NPC、AI BOSS王人变得栩栩欲活,仿佛有了我方的自主意志,或者和你交互对话,或者和你共同打怪,或者有针对性地与你对战。
另外,《诛仙天下》《inZOI》、《Dead Meat》、《AI People》、《异形:侠盗入侵》等游戏也将陆续加入ACE AI扮装或系统。
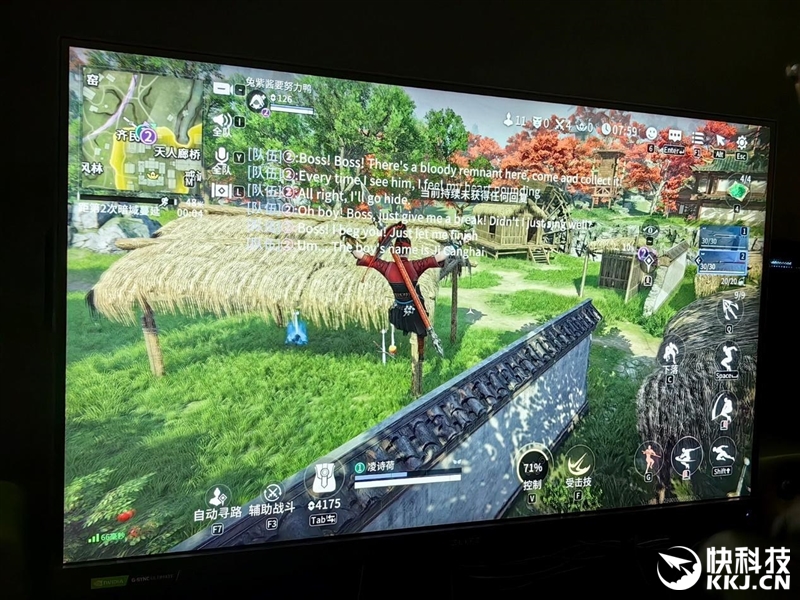
比如《长时连续手游》PC版,NVIDIA ACE 提供支柱的AI队友不错与玩家组队,并肩战争,找到所需的特定说念具,交换装备,提供解锁技能的建议,并作念出有助于取得见效的战争决策。
比如《动物一又克》,初次在端侧已毕了游戏内的 Diffusion图像生成,指引玩家在云海之上的飘浮厨房伸开对话和互动。
玩家可与盟友探究在职务中相聚到的谍报,也可前去船埠想象一艘新军舰,匡助雷顿(Rayton)与机械帝国作战。

再比如《神话5》,AI会评估真东说念主玩家的装备和缔造,将其与往日的对战进行比较,然后细则取得见效的最好行径决策。
因此,每一位玩家的BOSS对战王人是唯一无二的,即等于玩家再次击杀仍是被击败的BOSS,终端也可能澈底不同。

小结:
从硬件架构变革幅度上看,Blackwell算不上一次颠覆性的破损,然而在GPU发展史上,它注定是浓墨重彩的一笔,因为它将AI融入到了方方面面,以致可能是图形渲染技巧演化 的一次病笃滚动点。
按照传统的GPU发展念念路,咱们只可暴力增多GPU限度,包括增多晶体管与计较中枢数目、进步频率与功耗,来达成更好的性能,取得更好的画面和帧率。
尤其是在摩尔定律越走越坚苦,先进制程工艺仍是无法像从前那样带来显耀收益,半导体行业尤其是GPU行业,更需要从头念念考若何更好地走下去。
如今在AI的加抓下,一条新路正在越走越宽,从图形画面的渲染,到后光旅途的跟踪,再到游戏扮装的塑造,王人不错借助AI更高效地达成更好的遵守。
或者你会觉得这是见风使舵,这是舞弊,但其实,这或者才是GPU乃至通盘半导体发展的将来。
天然,现不才定论还为时过早,一切如故留给时分去锤真金不怕火吧。
咫尺,咱们正在对RTX 5090D进行焦躁的评测,将在第一时分为公共送上,敬请期待!
