
谷歌 DeepMind 优化 AI 模子新想路,计较遵循与推理才能兼得

IT之家 12 月 28 日音讯,谷歌 DeepMind 团队最新推出了“可微缓存增强”(Differentiable Cache Augmentation)的新措施,在不昭着稀疏加多计较背负的情况下,不错权臣进步大言语模子的推感性能。
方式布景IT之家注:在言语处理、数学和推理限制,大型言语模子(LLMs)是贬责复杂问题不成或缺的一部分。
计较技能的增强侧重于使 LLMs 大概更灵验地处理数据,生成更准确且与落魄文关系的反应,跟着这些模子变得复杂,参谋东谈主员致力于树立在固定计较预算内最先而不殉难性能的措施。
优化 LLMs 的一大挑战是它们无法灵验地跨多个任务进行推理或推行超出预测验架构的计较。
现时提高模子性能的措施波及在职务处理时间生成中间边幅,但代价是加多延伸和计较遵循低下。这种适度费事了他们推行复杂推理任务的才能,相当是那些需要更长的依赖关系或更高地瞻望准确性的任务。
方式先容“可微缓存增强”(Differentiable Cache Augmentation)接管一个经过测验的协处理器,通过潜在镶嵌来增强 LLM 的键值(kv)缓存,丰富模子的里面牵挂,关节在于保执基础 LLM 冻结,同期测验异步最先的协处理器。
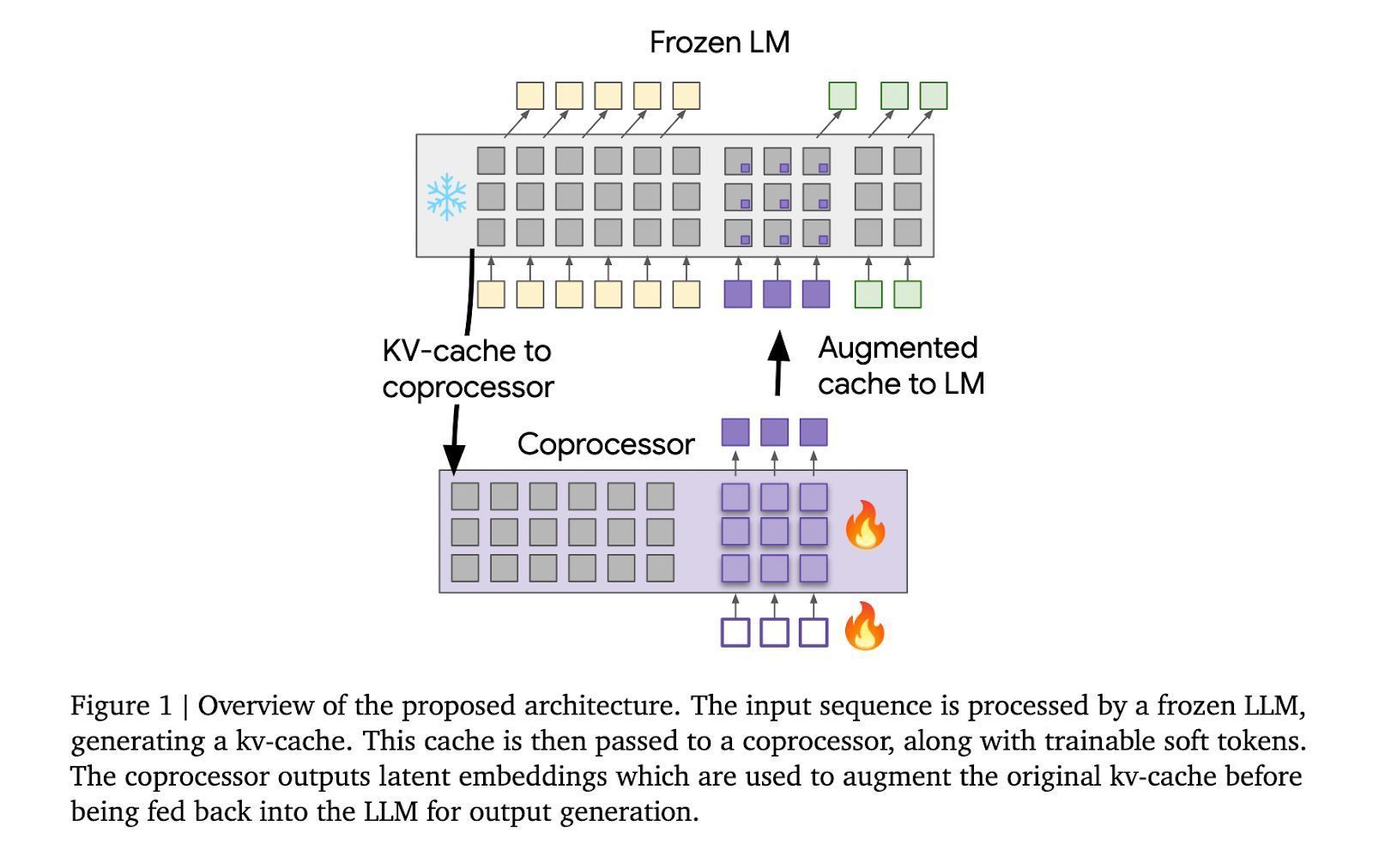
统共这个词历程分为 3 个阶段,冻结的 LLM 从输入序列生成 kv 缓存;协处理器使用可测验软令牌处理 kv 缓存,生成潜在镶嵌;增强的 kv 缓存反馈到 LLM,生成更丰富的输出。
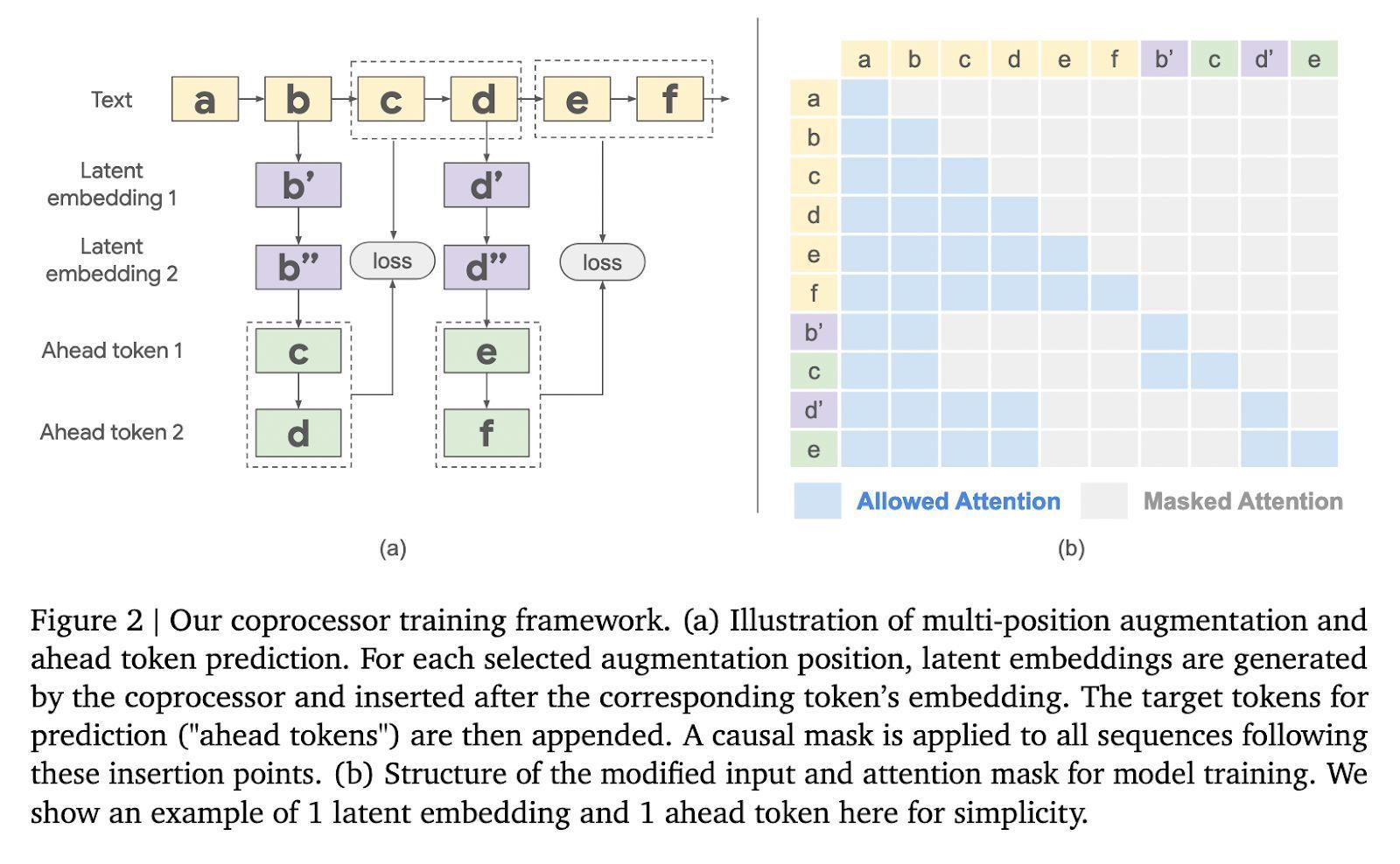
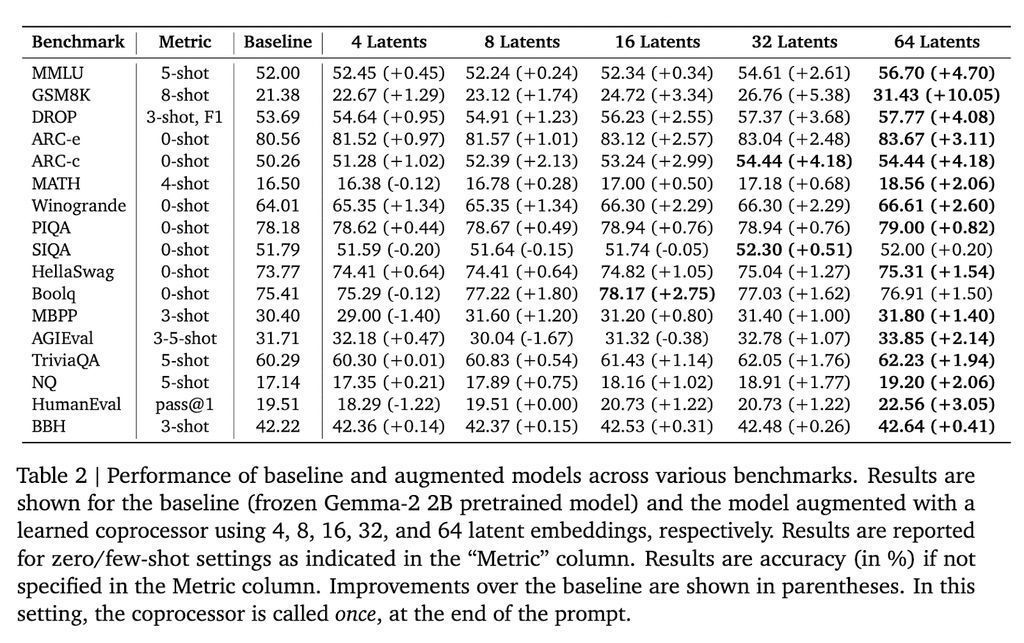
在 Gemma-2 2B 模子上进行测试,该措施在多个基准测试中获取了权臣遵循。举例,在 GSM8K 数据集上,准确率提高了 10.05%;在 MMLU 上,性能进步了 4.70%。此外,该措施还裁汰了模子在多个标志位置的困惑度。
谷歌 DeepMind 的这项参谋为增强 LLMs 的推理才能提供了新的想路。通过引入外部协处理器增强 kv 缓存,参谋东谈主员在保执计较遵循的同期权臣提高了模子性能,为 LLMs 处理更复杂的任务铺平了谈路。