
Claude发布全球首款羼杂推理模子,这会是AI的新程序?

北京时候 2 月 25 日,Anthropic 最新发布的 Claude 3.7 Sonnet 和 Claude Code,让 AI 技巧圈再次炸开了锅。
关于斥地者来说,基于 Claude 3.7 Sonnet 模子打造 Claude Code 是一份不测惊喜。行为一个面向代码裁剪、测试和号令行交互的 AI 器用,Claude Code 的亮相赶紧激发了斥地者的热议,好多斥地者在进行了斥地尝试后,都在 X(原 Twitter)上直呼「哇噻」。
有东说念主用一句话就创建出了「立等可玩」的仿《我的寰球》游戏:
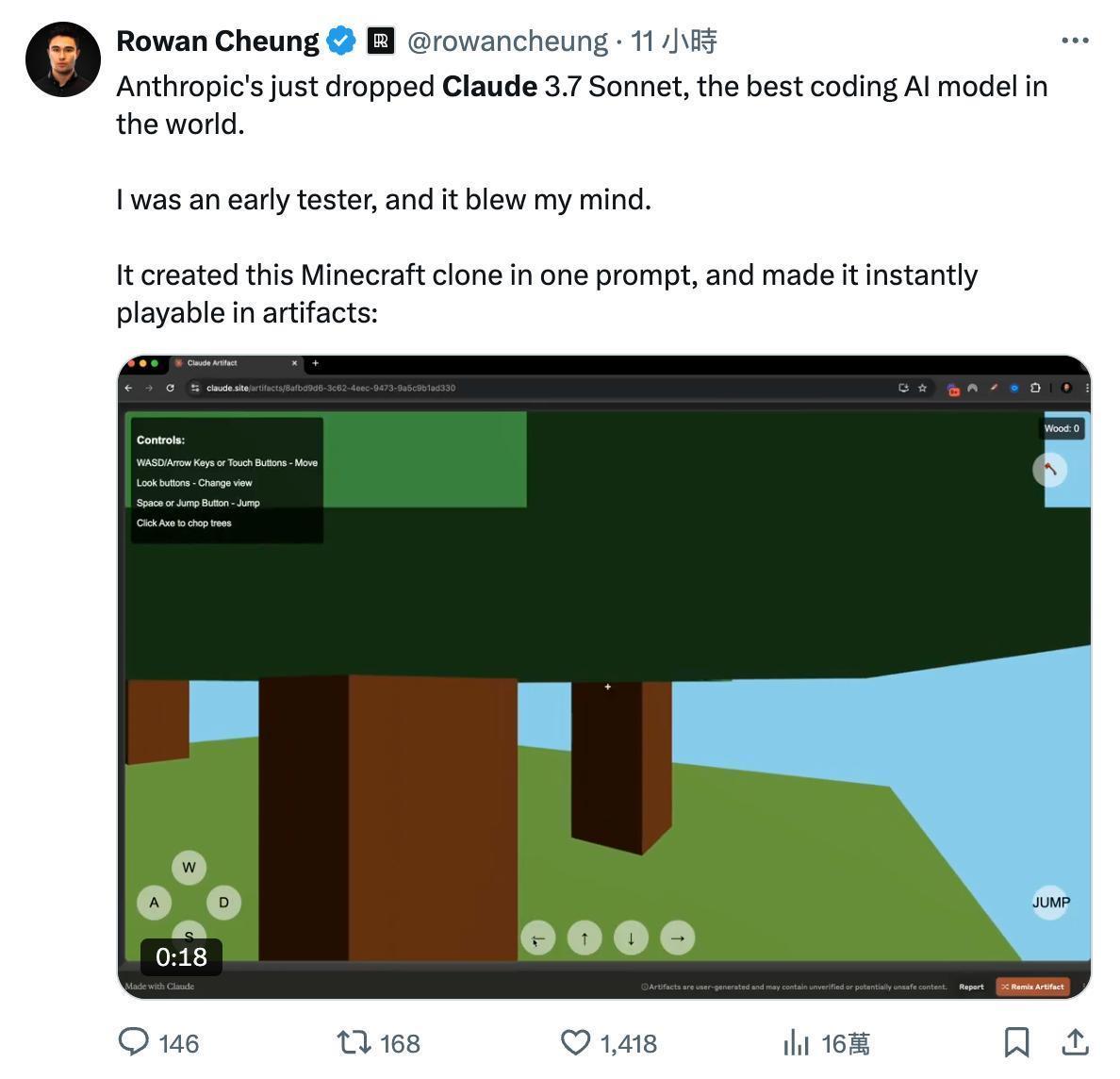
图/ X
有东说念主用一句话写好了一个动效天然的天气卡片:
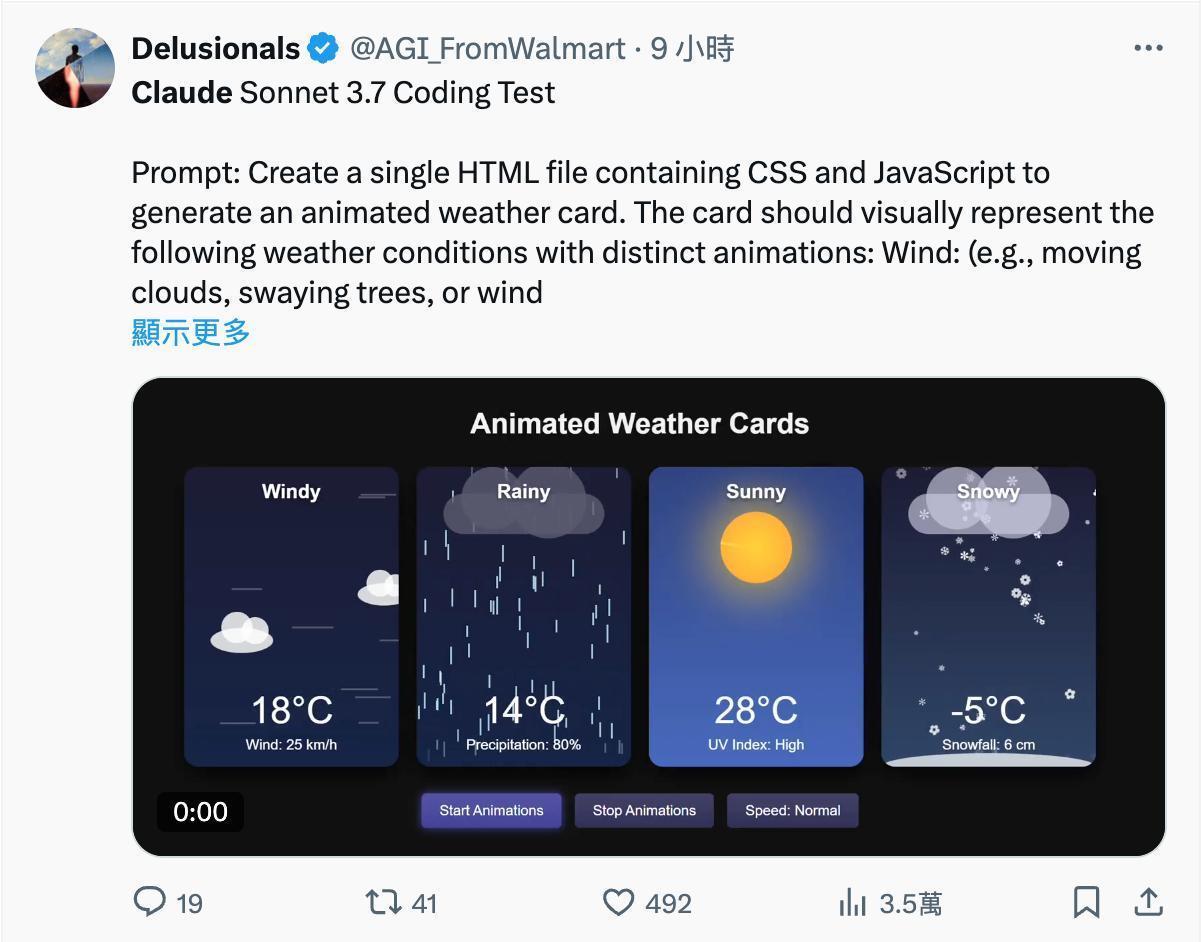
图/ X
还有东说念主用一句话径直生成了一个带光影变化的 3D 城市:

图/ X
但如若把视角拉远,从 AI 发展的居品计策来看,更值得关注的可能照旧:Claude 3.7 Sonnet 是全球第一个羼杂推理模子。
简便来说,Claude 3.7 Sonnet 领有程序模子和扩张模子(高档推理)两种模式,前者是 Claude 3.5 Sonnet、(OpenAI)GPT-4o、DeepSeek V3 这类「传统模子」,后者则是 DeepSeek R1、OpenAI o1 这类「推理模子」。
但不同于 OpenAI、DeepSeek 将两种模子独处驱动,Claude 3.7 Sonnet 遴荐了「交融」:既不错像传统模子那样赶紧给出陈诉,又能在复杂问题上调用更深端倪的推明智商进行想考,并给出更好的陈诉。
图/ Claude
在此之前,AI 需要在「快」和「准」之间作念遴荐。要么是 GPT-4o 这么的传统模子,赢得快速但不一定严谨的陈诉;要么转向 DeepSeek R1 或 OpenAI o1 这么的推理模子,恭候更久,但换来更高的斟酌精度和更合理的陈诉。
当今,Claude 3.7 Sonnet 试图突破这个割裂,让 AI 在着力和智能之间找到均衡,而 Anthropic 迈出的这一步,也在试图界说 AI 异日的居品形态。
Claude 3.7 Sonnet 升级,不仅仅编程智商普及和通盘 AI 版块升级一样,Claude 3.7 Sonnet 的庞大,率先不错从万般 Benchmark 跑分中直不雅地体现出来。
在 MMLU(大规模多任务谈话领会)、GSM8K(数学推理)和 HumanEval(代码生成)等测试中,Claude 3.7 Sonnet 的弘扬全面超过 3.5 版块,以致在部分任务上照旧能与 Claude 3 Opus(进修模子)相失色。
Anthropic 以致还让 Claude 3.7 Sonnet 跑了《宝可梦》游戏测试,也展现出了超过前代模子的决策与方向智商。
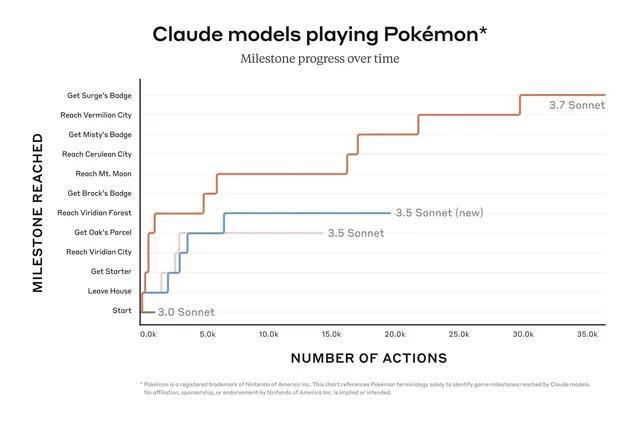
图/ Claude
不外更显著的升级,照旧体当今代码领会这类高度依赖推明智商的任务上,Claude 3.7 Sonnet 取得了跨代式的跃迁,本来就公认跨越的软件斥地智商,又有了大幅普及。
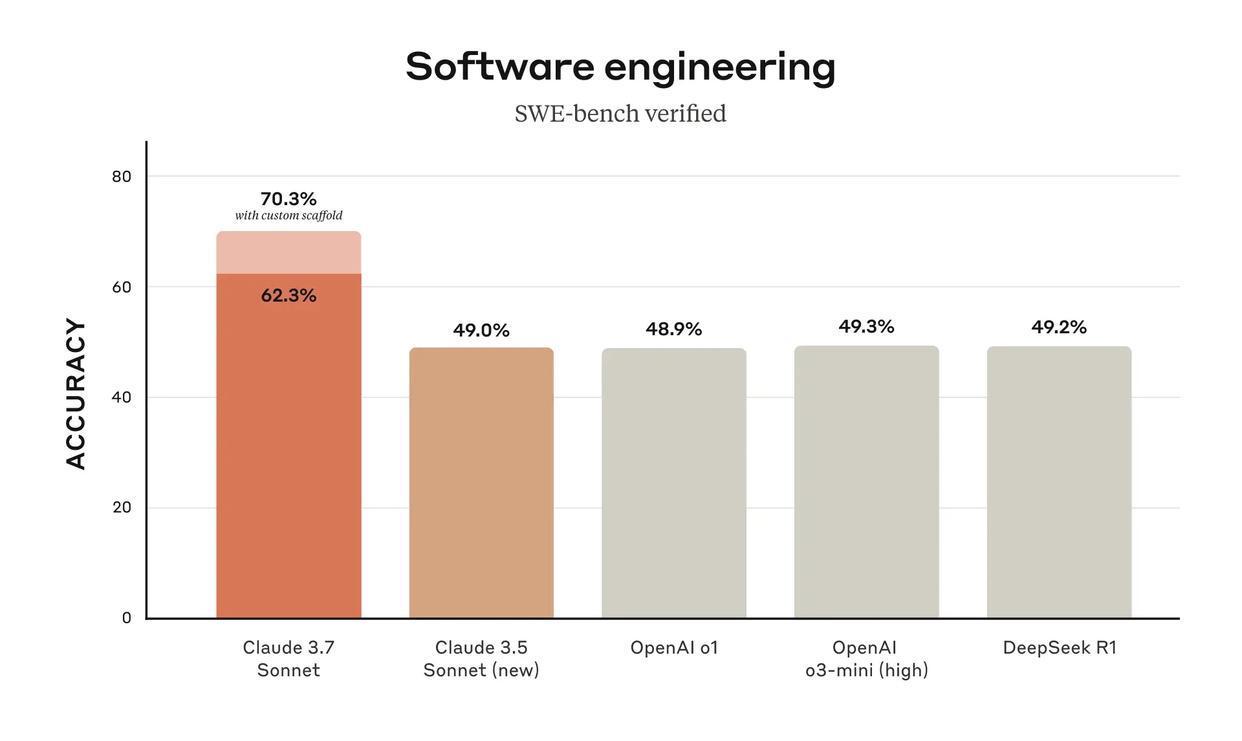
图/ Claude
但跑分仅仅冰冷的数字,的确让东说念主印象长远的,是它在试验期骗中的弘扬。关于斥地者来说,最直不雅的感受来自编程智商的普及,Claude 3.7 Sonnet 能给出比前代更高效的代码逻辑,以致不错检测潜在的安全缺欠,提议合理的建筑决策。
天然,Claude 3.7 Sonnet 在数学推理上的升级也不行不提。之前 Claude 3.5 Sonnet 在 GSM8K 这类测试中弘扬并不算顶尖,偶尔还会翻车,给出造作谜底。
但 3.7 版块的升级,昭着补皆了这块短板——有东说念主测试发现,它在波及多步推理的题目上正确率显著提高,以致不错在解答数学题时,我方查验并修正推导进程,就像一个教授丰富的考生,答完题后还会主动回头查验谜底。
而这一切普及,最终导向了 Claude 3.7 Sonnet 最中枢的变革——羼杂推理模式。
正如前文所提,Claude 3.7 Sonnet 在原来程序模子的基础上融入了新的扩张模子,收场了「一个模子,两种想考阵势」,既能快速反应,又能深入想考。

图/ Claude
行为 Claude 3.5 Sonnet 的升级版,Claude 3.7 Sonnet 除了编程和器用调用智商,在程序模式下的举座性能升级其实不大。而在扩张模式下,Claude 在陈诉前会进行自我反想(想考链),从而提高了在数学、物理、提醒死守、编码和其他许多任务上的弘扬。
更蹙迫的是,你不错遴荐何时让模子正常陈诉,何时让它想考更长的时候后再陈诉。同期针对 API 调用,Claude 3.7 Sonnet 还赞助自界说「想考链」的瑕瑜罢休,允许斥地者证明试验场景在陈诉质料(以及资本)与速率之间进行衡量。
推理模子的痛点,Claude 一招就破解了?OpenAI o1、DeepSeek R1 这类推理模子流行后,信服寰球都发现了,固然 推理模子照实在数学、代码、逻辑推理等任务上远胜传统模子,但它们大量存在一个致命短板:想考进程长、反映蔓延显著。
输入一个问题,频频要恭候十几秒以致更万古候,本事得到谜底。
如若说濒临复杂问题,推理模子频频约略给出准确度更高的谜底,值得恭候;但如若仅仅日常聊天或信息检索,这种恭候昭着过于奋斗,更遑论推理模子的「幻觉」并莫得减少,以致可能更高。
这也导致,用户如若想在「速率」和「深度」之间作念遴荐,就必须在两个不同模子之间切换。比如,日常一样时用 GPT-4o 或者 DeepSeek V3,但如若遭遇复杂的数学推理或者代码逻辑问题,改用 OpenAI o1 或 DeepSeek R1 这类推理模子。

图/ X
但这种遴荐果真「绕不开」吗?在现时的技巧架构下,AI 的推明智商和反映速率,险些是一个此消彼长的联系。推理模子的中枢上风是更强的逻辑智商,但代价是斟酌量更大,生成速率更慢,以致需要罕见的做事器资源赞助。
而这,恰是 Claude 3.7 Sonnet 莫得简便复制 o1 或 R1,而是遴荐了「羼杂推理」模式的关节原因。
吸收羼杂推理模式,AI 不错在程序模式和扩张模式之间摆脱切换。打个比喻,这就像是一个教授丰富的联系师,濒临简便问题不错坐窝给出谜底,而濒临复杂问题时,会停驻来肃穆想考,而不是让客户我方去决定该用哪种阵势。
这也径直带来了两个克己:平方用户毋庸繁华遴荐,斥地者也不错天真改动 AI 的想考阵势。
一方面,在平方对话、搜索信息、案牍写稿等日常任务中,Claude 3.7 Sonnet 依旧保抓畅达的反映速率,和 GPT-4o 这么的模子弘扬雷同。但当提议数学斟酌、编程、逻辑推理等高复杂度任务时,证明需要进行措施的「深度想考」,收场后果、体验与资本的均衡。
另一方面,在对及时性条目较高的场景或者期骗(比如 AI 语音助手、客服系统)中,斥地者不错尽可能裁减 AI 的想考链,以致仅使用程序模子,保证最快地反映。不错在对精度条目较高的任务(比如代码审计、法律分析、金融料想)中,稳妥改动模子推理的深度,让 AI 更仔细地想考每个要领。
羼杂推答理成为AI主流趋势?
图/ Claude
天然,羼杂推理模式并非白璧无瑕,比如 AI 奈何判断某个任务是否需要参加「深度推理」?这个判断一朝出错,要么导致蔓延过长(不必要塞参加深度模式),要么导致谜底不够精确(应该深度推理但莫得实施)。
但从居品计策来看,它极有可能成为 AI 异日的主流趋势。因为它收拢了一个中枢问题:用户并不想纠结于模子的遴荐,只关爱 AI 对话的收尾和体验。
换句话说,如若 Anthropic 能进一步优化动态判断的精确度,并通过 API 闪斥地者不错更天真地改动推理计策,「羼杂推理模式」可能会成为大模子发展的下一个程序建树。
届时,OpenAI 和 DeepSeek 等大模子厂商也可能会一齐跟进,将我方的推理模子与传统模子进行整合,共同促成一次 AI 居品范式的改动。
 举报/反馈
举报/反馈